Fine-tuning des LLM : le guide complet 2026 pour adapter les modèles d’IA générative à vos données métier, votre jargon et vos formats spécifiques.
Fine-Tuning: Adapter l’IA à vos besoins réels.
Résumé
Le fine-tuning (ou ajustement fin) est une technique qui consiste à réentraîner partiellement un grand modèle de langage (LLM) déjà pré-entraîné sur un jeu de données spécifique à un domaine, un style ou une tâche. En 2026, il devient accessible aux entreprises grâce à des API (OpenAI, Google, Anthropic) et à des méthodes param-efficaces comme LoRA. Ce guide explique les cas d’usage, les différences avec le RAG, les coûts, les étapes pratiques et les bonnes performances pour transformer un modèle générique en un assistant expert sur-mesure.
Table des matières
- Qu’est-ce que le fine-tuning ? Définition et principes
- Fine-tuning vs RAG : comparatif détaillé
- Quand utiliser le fine-tuning ?
- Les principales méthodes de fine-tuning
- Modèles fine‑tunables en 2026 (open source et API)
- Guide pratique : fine-tuner un modèle pas à pas
- Coûts et optimisation
- Bonnes pratiques et pièges à éviter
- Tendances 2026 : LoRA, QLoRA, fine-tuning multi-modèle
- FAQ
1. Qu’est-ce que le fine-tuning ? Définition et principes
Fine-tuning (ajustement fin) : technique d’apprentissage supervisé consistant à initialiser un modèle de langue avec les poids d’un LLM pré-entraîné (ex: GPT-5, Llama 3), puis à poursuivre son entraînement sur un jeu de données plus restreint et spécifique à une tâche cible. Contrairement à l’entraînement from scratch, elle tire parti des connaissances déjà acquises.
Un LLM pré-entraîné a vu des centaines de milliards de tokens issus d’internet, de livres, de code, etc. Il connaît la grammaire, le raisonnement de base et une vaste culture générale. Mais il ne maîtrise pas votre jargon juridique, le format précis de vos rapports, ni la structure de sortie dont votre application a besoin.
Le fine-tuning corrige cela en exposant le modèle à vos exemples. Par exemple, vous lui montrez 500 paires (instruction, réponse idéale) issues de votre service client. Le modèle ajuste ses poids pour privilégier ce style et ces connaissances. À la fin, il répond comme un agent formé en interne.
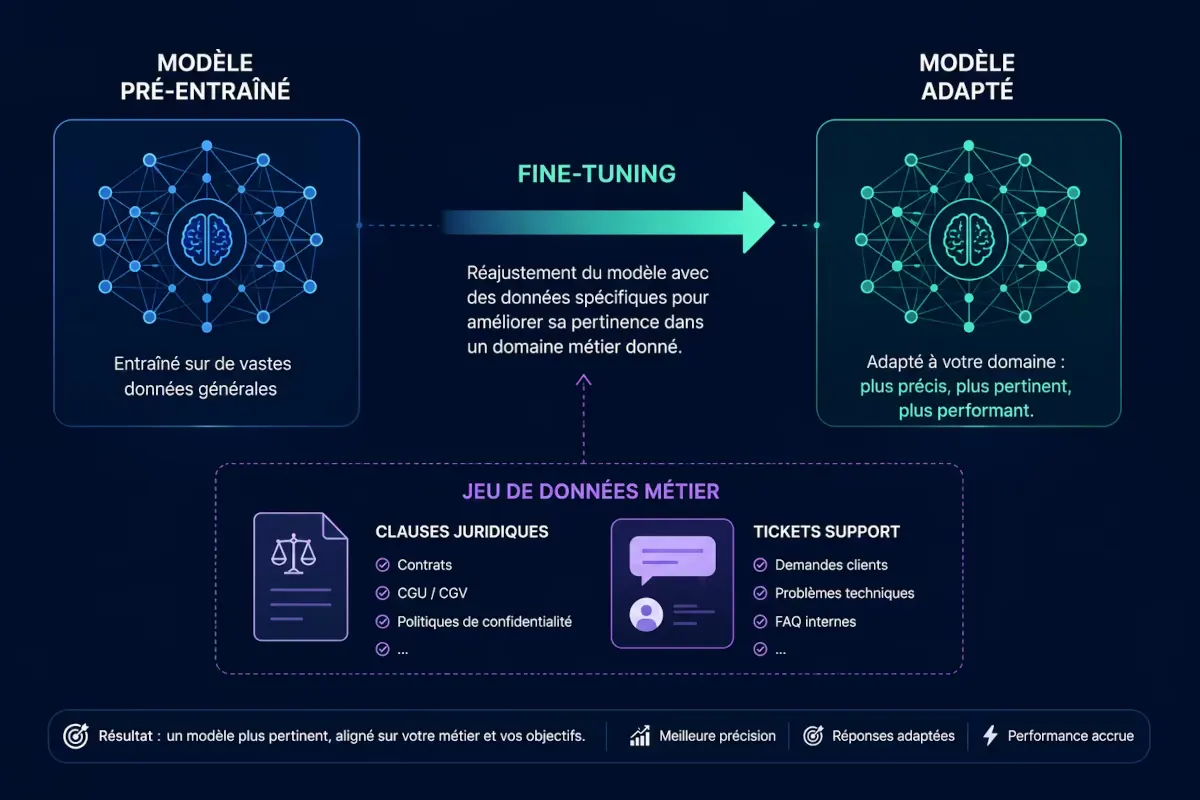
Figure 1 — Principe du fine-tuning : le modèle pré-entraîné (socle de connaissances générales) est ajusté sur vos exemples métier pour devenir un modèle spécialisé.
En 2026, selon OpenAI (mars 2026) , plus de 40 % des entreprises utilisant GPT-5 en production ont fine‑tuné le modèle au moins une fois, principalement pour des cas d’usage de support client, d’analyse contractuelle et de génération de code métier.
2. Fine-tuning vs RAG : comparatif détaillé
Le choix entre fine-tuning et RAG est l’une des questions les plus fréquentes. Plutôt que de les opposer, voici un tableau clair.
| Critère | Fine-tuning | RAG |
|---|---|---|
| Où sont stockées les connaissances spécifiques ? | Dans les poids du modèle (entraînement) | Dans une base vectorielle externe (recherche) |
| Mise à jour des connaissances | Lourde : ré-entraînement complet ou partiel | Immédiate : il suffit d’ajouter/retirer des documents |
| Coût à l’inférence | Faible (pas de recherche vectorielle, prompt plus court) | Élevé (recherche + tokens de contexte) |
| Réduction des hallucinations | Limitée aux exemples vus (mais améliore la cohérence) | Forte (réponse contrainte par les documents) |
| Adaptation du ton/style/format | Excellente (apprend par imitation) | Limitée (un bon prompt peut suffire) |
| Confidentialité (pas de données externes) | Modèle auto-hébergé possible – données d’entraînement à protéger | Données toujours présentes dans la base vectorielle (sécurisable) |
| Volume de données spécifiques requis | Quelques centaines à milliers d’exemples | Potentiellement des millions de documents (pas d’entraînement) |
Stratégie gagnante en 2026 : utilisez le fine-tuning pour le comportement (style, structure, format de sortie, ton) et le RAG pour les connaissances factuelles (produits, documents internes, actualités). Les deux sont complémentaires : on peut fine-tuner un modèle pour qu’il réponde toujours en JSON, puis lui adjoindre un RAG pour qu’il aille chercher les données actualisées.
3. Quand utiliser le fine-tuning ?
Le fine-tuning n’est pas toujours nécessaire. Voici les situations où il apporte une vraie valeur.
Cas 1 – Format de sortie complexe et répétitif
Votre application doit produire des objets JSON strictement structurés (ex: { "nom": "...", "prix": "...", "stock": ... }). Le prompt engineering peut y arriver, mais avec un taux d’erreur non négligeable (5-10 %). Le fine-tuning sur 1 000 exemples JSON bien formés fait chuter l’erreur à moins de 1 %. Gain : fiabilité opérationnelle.
Cas 2 – Jargon métier et ton spécifique
Un cabinet d’avocats veut un assistant qui rédige des clauses juridiques avec le vocabulaire et la phraséologie maison. Un modèle générique parlera trop simplement. Le fine-tuning sur 500 clauses existantes lui apprend le style exact. Gain : acceptation par les experts.
Cas 3 – Réduction des coûts d’inférence
Un modèle fine‑tuné peut répondre correctement avec un prompt très court (parfois juste la question brute), là où le modèle générique nécessite plusieurs paragraphes d’instructions. Économie : jusqu’à 80 % de tokens d’entrée. Pour un volume élevé d’appels, l’économie dépasse le coût du fine‑tuning.
Cas 4 – Confidentialité et souveraineté
Vous hébergez un modèle open source (ex: Llama 3 70B) sur vos propres serveurs. Le fine-tuning se fait localement, aucune donnée ne quitte l’infrastructure. Idéal pour des données sensibles (santé, défense, RH).
4. Les principales méthodes de fine-tuning
En 2026, plusieurs approches cohabitent, du plus lourd au plus léger.
4.1 – Fine-tuning complet (Full fine-tuning)
Tous les poids du modèle sont mis à jour. C’est la méthode la plus expressive mais aussi la plus coûteuse en calcul et en stockage (chaque modèle fine‑tuné pèse autant que l’original). Réservée aux grandes entreprises avec des clusters GPU.
4.2 – LoRA (Low-Rank Adaptation)
La méthode star depuis 2024. Au lieu de mettre à jour toute la matrice de poids, LoRA injecte de petites matrices de rang faible dans chaque couche. Le nombre de paramètres entraînables passe de plusieurs milliards à quelques millions. Avantages : mémoire réduite, entraînement rapide, plusieurs adaptateurs LoRA peuvent cohabiter pour un même modèle de base.
4.3 – QLoRA (Quantized LoRA)
Combine LoRA avec une quantification (4 bits) du modèle de base. Permet de fine‑tuner un Llama 3 70B sur une seule GPU grand public (24 Go VRAM). Très populaire dans la communauté open source.
4.4 – Adapters / P‑tuning / Prefix tuning
Des méthodes encore plus légères, qui n’ajoutent qu’un petit réseau (adaptateur) entre les couches du modèle ou des préfixes entraînables dans l’espace d’embedding. Moins puissantes que LoRA, mais ultra‑rapides. Utiles pour des adaptations très ciblées (style, quelques instructions).
Recommandation 2026 : pour la plupart des usages, LoRA offre le meilleur compromis performance/coût. Pour les très gros modèles (400B) sur matériel limité, QLoRA s’impose.
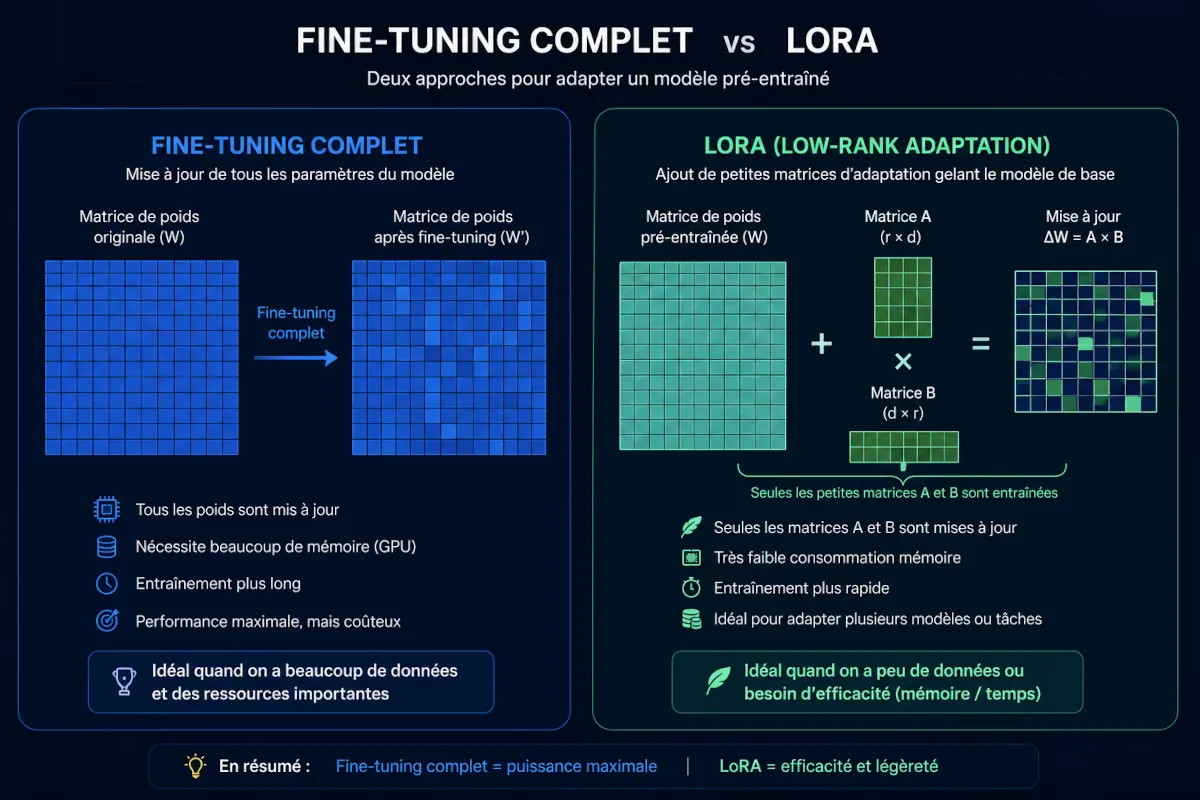
Figure 2 — Principe de LoRA : seules les matrices A et B sont entraînées, la matrice W originale reste gelée, réduisant drastiquement le nombre de paramètres.
5. Modèles fine‑tunables en 2026 (open source et API)
| Modèle | Taille | Méthode supportée | Coût d’entraînement (estimé) | Hébergement |
|---|---|---|---|---|
| GPT-5 (via API) | ~400B | Fine-tuning managé | $0,10 / 1K tokens | API OpenAI |
| GPT-4o (via API) | ~200B | Fine-tuning managé | $0,08 / 1K tokens | API OpenAI |
| Gemini 1.5 Pro/Flash | ~150B | Fine-tuning via Vertex | $0,15 / 1K tokens | API Google |
| Claude 3.5 Sonnet | ~175B | Fine-tuning bêta | sur devis | API Anthropic |
| Llama 3 (8B, 70B, 400B) | 8B-400B | LoRA, QLoRA, full | ~$200 (70B sur cloud) | Local / cloud |
| Mistral Large 2 | 123B | LoRA, full | ~$150 | Local / cloud |
| Qwen 2.5 (72B) | 72B | LoRA, full | ~$100 | Local / cloud |
| Command R (Cohere) | 104B | API fine-tuning | $0,10 / 1K tokens | API Cohere |
7. Guide pratique : fine-tuner un modèle pas à pas
Nous prenons l’exemple d’un fine-tuning via API OpenAI, le plus accessible. Les principes restent valables pour les modèles open source.
Étape 1 – Préparer votre jeu de données
Le format attendu par OpenAI est un fichier JSONL, chaque ligne étant un exemple de conversation. Pour un assistant métier :
{"messages": [{"role": "system", "content": "Tu es un assistant spécialisé dans la politique RH."}, {"role": "user", "content": "Quel est le délai de préavis pour un départ volontaire ?"}, {"role": "assistant", "content": "Selon l'article 12 du règlement intérieur, le préavis est de deux mois, sauf période d'essai où il est d'une semaine."}]}Bonnes pratiques :
- Au moins 50 à 100 exemples (souvent 500 pour de bons résultats)
- Couvrir les cas limites et les refus (“Je ne sais pas”)
- Inclure des exemples où le modèle doit reformuler poliment
Étape 2 – Valider et formater
Utilisez l’outil de validation OpenAI :
openai tools fine_tunes.prepare_data -f mes_donnees.jsonlÉtape 3 – Lancer le fine-tuning
from openai import OpenAI
client = OpenAI()
# Le fichier doit d'abord être uploadé
file = client.files.create(
file=open("mes_donnees.jsonl", "rb"),
purpose="fine-tune"
)
# Lancer le job
job = client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-4o-2024-11-20", # ou gpt-5
hyperparameters={
"n_epochs": 3,
"learning_rate_multiplier": 2.0,
"batch_size": 4
}
)Étape 4 – Surveiller et évaluer
OpenAI fournit une métrique loss et accuracy pendant l’entraînement. Une courbe de loss qui diminue régulièrement est un bon signe. Un overfitting se manifeste par une loss de validation qui remonte.
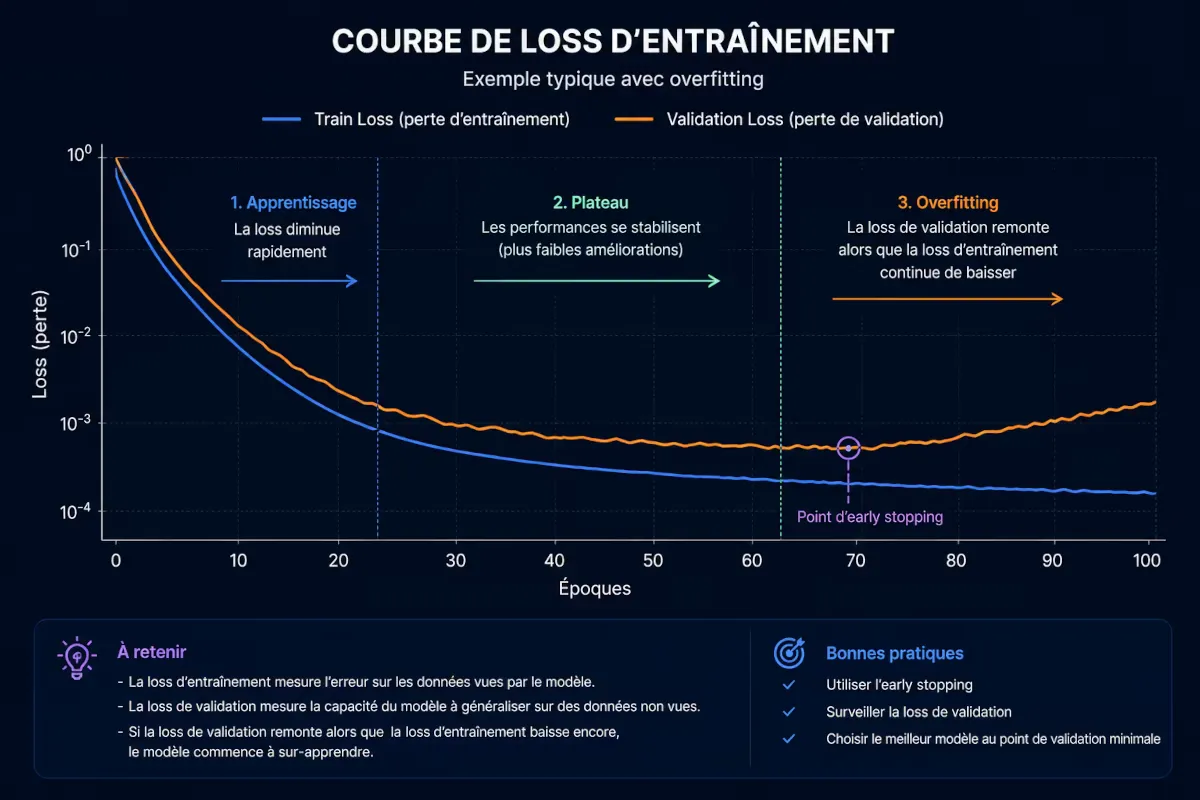
Figure 3 — Courbe de loss d’entraînement idéale : décroissance régulière puis plateau. Une remontée signale un sur-apprentissage.
Étape 5 – Tester le modèle fine‑tuné
completion = client.chat.completions.create(
model="ft:gpt-4o-2024-11-20:ma-societe::xyz",
messages=[{"role": "user", "content": "Nouvelle question"}]
)Étape 6 – Itérer
Rarement parfait du premier coup. Analysez les erreurs, complétez le dataset, relancez un fine-tuning (éventuellement à partir du modèle précédent).
7. Coûts et optimisation
Le fine-tuning a deux composantes de coût : l’entraînement et l’inférence.
Coût d’entraînement (API OpenAI)
- GPT-4o : $0,08 / 1K tokens d’entraînement
- GPT-5 : $0,10 / 1K tokens
- 100 000 tokens d’entraînement (environ 500 exemples) coûtent donc 8 à 10 dollars.
Coût d’inférence après fine-tuning
Le prix par token est le même que pour le modèle de base. Mais comme le prompt peut être plus court (car le comportement est déjà intégré), le coût total par requête diminue souvent.
Optimisations
- Utilisez LoRA (modèles open source) : réduit l’entraînement de 90 % en mémoire.
- Quantifiez : après fine-tuning, quantifiez le modèle en 8 bits pour inférence plus rapide.
- N’entraînez que les couches supérieures : parfois suffisant pour un changement de style.
Économie typique : une entreprise qui fine‑tune GPT-4o sur 2 000 exemples (≈ 400 000 tokens) paie ~32 dollars d’entraînement. Elle réduit ensuite ses prompts de 800 tokens à 200, économisant 75 % du coût d’inférence sur des millions de requêtes. Rentabilité rapide.
8. Bonnes pratiques et pièges à éviter
Piège n°1 – Données de faible qualité ou contradictoires
Des exemples bruités ou incohérents (parfois “Oui” parfois “Non” pour la même question) rendent le modèle instable. Solution : faites relire vos exemples par plusieurs annotateurs, calculez l’accord inter‑annotateur.
Piège n°2 – Sous‑représentation des cas négatifs
Si vous n’avez que des exemples où le modèle doit répondre, il ne saura jamais dire “Je ne sais pas”. Solution : ajoutez 10‑20 % d’exemples où la réponse correcte est un refus poli.
Piège n°3 – Surapprentissage (overfitting)
Un modèle qui obtient 100 % d’exactitude sur l’entraînement mais échoue sur les tests est inutilisable. Solution : séparez 15 % des données en validation, surveillez la loss, limitez le nombre d’époques (généralement 3 à 5).
Piège n°4 – Négliger l’évaluation humaine
Les métriques automatiques (loss, F1) ne capturent pas la qualité perçue. Solution : faites évaluer en aveugle par des utilisateurs finaux sur un panel de cas réels.
Checklist avant lancement : (1) au moins 50 exemples propres et diversifiés, (2) format validé, (3) jeu de test séparé, (4) métriques cibles définies, (5) plan pour itérer après premier résultat.
9. Tendances 2026 : LoRA, QLoRA, fine-tuning multi-modèle
LoRA devient le standard
L’énorme avantage de LoRA – pouvoir avoir un seul modèle de base (par ex Llama 3 70B) et des centaines d’adaptateurs (un par client, un par tâche) – en fait la méthode préférée des fournisseurs de modèles open source. Les adaptateurs LoRA ne pèsent que quelques centaines de mégaoctets.
QLoRA démocratise l’accès
L’exécution de QLoRA sur une seule carte graphique grand public a permis aux petites entreprises de fine‑tuner des modèles jusqu’à 70B sans infrastructure lourde.
Fine-tuning multimodal
Des modèles comme GPT-4o ou Gemini 2.5 Pro acceptent désormais des images en entrée. Le fine-tuning multimodal permet d’apprendre à un modèle à extraire des informations de graphiques ou de photos. Google Vertex AI propose un fine-tuning pour Gemini 1.5 Pro avec capacités vision.
Instruction tuning et reinforcement learning
Au-delà de la simple imitation, les méthodes RLHF (Reinforcement Learning from Human Feedback) affinent le modèle pour privilégier des réponses préférées. C’est la technique utilisée par OpenAI pour passer de GPT-4 à GPT-4o. Elle reste plus complexe à mettre en œuvre en interne.
Revenir au guide complet
Cet article fait partie du guide complet sur l’IA générative en entreprise qui couvre l’ensemble des concepts, outils et applications liés à ce domaine.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
FAQ
Qu'est-ce que le fine-tuning d'un LLM ?
Le fine-tuning (ou ajustement fin) est une technique d'apprentissage supervisé qui consiste à reprendre un modèle de langage déjà pré-entraîné sur des données massives (ex: GPT-5, Llama 3) et à poursuivre son entraînement sur un jeu de données plus petit et spécifique à une tâche ou un domaine. Cela permet d'adapter le comportement, le style ou les connaissances du modèle sans repartir de zéro.
Quelle est la différence entre fine-tuning et RAG ?
Le RAG ajoute des connaissances externes au moment de l'inférence sans modifier le modèle, tandis que le fine-tuning intègre ces connaissances dans les poids du modèle via un réentraînement. Le RAG est idéal pour des données volatiles ou très volumineuses ; le fine-tuning pour un style, un format ou une compétence récurrente. Ils sont complémentaires : on peut fine-tuner un modèle pour qu'il structure ses réponses, puis lui adjoindre un RAG pour des faits actualisés.
Quand faut-il utiliser le fine-tuning plutôt qu'un simple prompt engineering ?
Le prompt engineering suffit souvent (80% des cas). Le fine-tuning devient nécessaire lorsque vous avez besoin d'une fiabilité élevée sur un format de sortie complexe (JSON structuré, jargon métier), d'une réduction des coûts (moins de tokens de prompt), d'une confidentialité absolue (modèle hébergé localement), ou d'un gain de latence (réponses plus courtes et directes). Il est aussi utile pour corriger des biais comportementaux systématiques.
Combien coûte le fine-tuning d'un LLM ?
Le coût varie selon le modèle et la taille du jeu de données. Pour un fine-tuning complet de GPT-5 via API OpenAI, comptez environ 0,10 $ à 0,50 $ pour 1 000 tokens d'entraînement. Un jeu de 50 000 tokens coûte donc 5 à 25 dollars. Pour un modèle open source comme Llama 3 (70B) hébergé sur cloud, l'entraînement sur 10 000 exemples peut atteindre 200 à 500 dollars. Des méthodes param-efficients comme LoRA réduisent le coût de 90 à 95 %.
Quelles sont les méthodes de fine-tuning les plus courantes ?
On distingue le fine-tuning complet (tous les poids sont mis à jour – coûteux), le fine-tuning param-efficace (LoRA, QLoRA, adaptateurs) qui ne modifie qu'une petite fraction des paramètres, et le fine-tuning d'instructions (instruction tuning) qui apprend à suivre des consignes. En 2026, LoRA (Low-Rank Adaptation) domine pour les modèles open source, tandis que les API propriétaires proposent du fine-tuning managé.
Quels modèles peut-on fine-tuner en 2026 ?
Les principaux modèles accessibles en fine-tuning sont : GPT-5 et GPT-4o via API OpenAI ; Gemini 1.5 Pro/Flash via Google Vertex AI ; Claude 3.5 Sonnet via Anthropic ; les modèles open source Llama 3 (8B, 70B, 400B), Mistral Large 2, Qwen 2.5, et Command R (Cohere). Le choix dépend de vos contraintes de coût, confidentialité et performance.
Quelles sont les bonnes pratiques pour préparer un jeu de données de fine-tuning ?
Privilégiez la qualité sur la quantité : quelques centaines d'exemples bien choisis valent mieux que 50 000 exemples bruités. Utilisez un format cohérent (ex: messages ChatGPT). Équilibrez les classes, dédupliquez, et vérifiez l'absence d'informations sensibles. Séparez systématiquement en train/validation/test. Évaluez sur un jeu de test hors échantillon.
Le fine-tuning résout-il le problème des hallucinations ?
Partiellement. Le fine-tuning peut réduire les hallucinations sur les sujets et formats bien représentés dans les données d'entraînement. Il ne garantit pas l'absence d'hallucination en dehors de ces exemples. Pour des faits précis, le RAG reste plus adapté. La meilleure approche combine fine-tuning (pour le comportement) et RAG (pour les faits actualisés).
Sources
- OpenAI (mars 2026) – Fine-tuning GPT-5 and GPT-4o: Best Practices
- Google DeepMind (janvier 2026) – Gemini 1.5 Pro fine-tuning documentation
- Hu, E. et al. (2022) – LoRA: Low-Rank Adaptation of Large Language Models (ICLR 2022)
- Dettmers, T. et al. (2024) – QLoRA: Efficient Finetuning of Quantized LLMs (NeurIPS)
- Bouchard, G. et al. (2025) – Structured Output Fine-tuning: A Comparative Study
- Intercom (2026) – The ROI of Fine-tuning for Customer Support
- Hugging Face (2026) – State of Open-Source LLM Fine-tuning 2026
- McKinsey (avril 2026) – The economics of adapting foundation models
Article mis à jour en mai 2026. Les prix et capacités des modèles évoluent rapidement ; consultez les pages officielles pour les données les plus récentes.