RAG (Retrieval-Augmented Generation) : le guide complet 2026 pour comprendre et déployer cette architecture qui rend les IA génératives réellement fiables en entreprise.
Résumé
Le RAG (Retrieval-Augmented Generation) est une architecture d’IA qui combine un moteur de recherche vectorielle avec un LLM (grand modèle de langage). Avant de générer une réponse, le système va chercher dans une base de connaissances les passages pertinents, puis les injecte comme contexte au modèle. Cette approche, née chez Meta en 2020, est devenue en 2026 la méthode de référence pour lutter contre les hallucinations, donner accès à des données privées sans réentraînement, et citer des sources vérifiables. Ce guide couvre le fonctionnement technique, les cas d’usage concrets, les outils (LangChain, LlamaIndex, bases vectorielles), les défis (latence, qualité des données) et les tendances 2026 (RAPTOR, self-RAG, agents RAG).
Table des matières
- Qu’est-ce que le RAG ? Définition et origine
- Pourquoi le RAG est devenu incontournable en 2026
- Fonctionnement technique : les trois étapes clés
- Les composants d’une architecture RAG
- Cas d’usage concrets en entreprise
- RAG vs fine-tuning : comment choisir ?
- Guide pratique pour déployer un RAG
- Les principaux défis et leurs solutions
- Tendances 2026 : RAPTOR, self-RAG, agents et multimodal
- FAQ
1. Qu’est-ce que le RAG ? Définition et origine
RAG (Retrieval-Augmented Generation) : architecture d’IA générative qui enrichit le prompt d’un LLM avec des documents pertinents extraits dynamiquement d’une base de connaissances. Le modèle ne répond donc pas seulement de sa mémoire paramétrique (ses poids), mais s’appuie sur des informations actualisées et vérifiables.
Pour comprendre l’importance du RAG, il faut d’abord saisir la limite fondamentale des LLM classiques. Un modèle comme GPT-4 ou Gemini a été entraîné sur des données arrêtées à une date donnée (octobre 2023 pour GPT-4, mai 2025 pour GPT-5). Il ignore tout ce qui s’est passé après. Pire encore : il peut halluciner — inventer des faits, des citations, des chiffres — avec une assurance déconcertante, simplement parce qu’il ne trouve pas l’information dans sa mémoire.
C’est dans ce contexte que des chercheurs de Meta (Lewis et al., 2020) ont publié l’article fondateur “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. L’idée était révolutionnaire : séparer la mémoire des faits de la capacité de génération. Plutôt que de tout stocker dans les poids du réseau de neurones, on confie la recherche d’information à un moteur dédié, et le LLM se concentre sur la formulation.
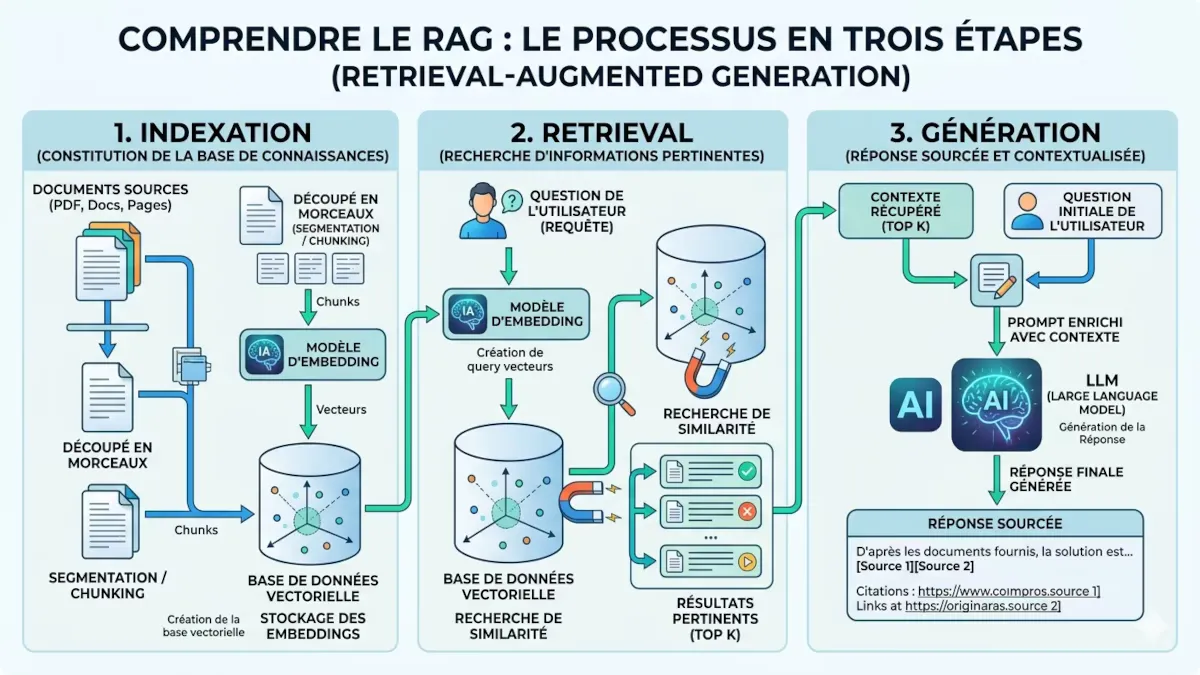
Figure 1 — Architecture simplifiée du RAG : la requête utilisateur sert à rechercher des documents pertinents dans une base vectorielle ; ces documents sont ajoutés au contexte du LLM, qui génère une réponse sourcée.
En 2026, le RAG est devenu le standard de facto pour toute application sérieuse d’IA générative en entreprise. Selon Gartner (janvier 2026) , plus de 65 % des déploiements de LLM en production intègrent une couche RAG, contre moins de 15 % en 2024.
2. Pourquoi le RAG est devenu incontournable en 2026
L’adoption fulgurante du RAG repose sur trois atouts majeurs.
2.1 — La fin (partielle) des hallucinations
Le RAG ne résout pas miraculeusement toutes les hallucinations, mais il les réduit drastiquement. En contraignant le LLM à répondre à partir des documents fournis — et en lui demandant de dire “je ne sais pas” si l’information est absente — les taux d’erreur factuelle chutent. Selon une étude de Contextual AI (2025) , un pipeline RAG bien paramétré divise par trois le nombre de réponses hallucinées par rapport à un LLM seul (passant de 12 % à environ 4 % d’affirmations non vérifiables).
2.2 — L’accès à des données privées et actualisées
Un LLM classique ne connaît pas vos documents internes (contrats, notes de frais, bases techniques, e-mails). Pour y accéder, deux options : le fine-tuning (coûteux et figé dans le temps) ou le RAG. Avec le RAG, il suffit d’ajouter un nouveau document dans la base vectorielle pour qu’il soit immédiatement pris en compte, sans aucune formation supplémentaire du modèle.
2.3 — La traçabilité et la confiance
Dans un environnement professionnel régulé, “l’IA a dit” ne suffit pas. Il faut pouvoir justifier. Le RAG permet de citer les sources : le système peut retourner non seulement la réponse, mais aussi les passages exacts de vos documents qui l’ont fondée. C’est une exigence courante dans le conseil juridique, la santé ou la finance.
3. Fonctionnement technique : les trois étapes clés
Un pipeline RAG suit invariablement le même enchaînement, que l’on peut décomposer en trois phases : indexation, retrieval (recherche) et génération.
Étape 1 : Indexation (préparation des connaissances)
Cette phase est réalisée une fois, avant toute interaction utilisateur. Elle consiste à transformer vos documents (PDF, Word, HTML, bases de données) en un format interrogeable par similarité sémantique.
- Découpage (chunking) : un document long est divisé en fragments (généralement 200 à 1 000 tokens) pour faciliter la recherche. Un chunk trop petit perd le contexte ; un chunk trop grand introduit du bruit.
- Génération des embeddings : chaque chunk est converti en vecteur numérique (une série de centaines ou milliers de nombres flottants) par un modèle spécialisé. Ce vecteur “encode” le sens sémantique du passage. Les modèles courants en 2026 sont
text-embedding-3-large(OpenAI),voyage-2(Voyage AI), ougte-Qwen2-7B(open source). - Stockage en base vectorielle : les couples (chunk, embedding) sont stockés dans une base vectorielle qui permettra plus tard de rechercher les chunks les plus proches sémantiquement d’une requête.
from openai import OpenAI
import numpy as np
client = OpenAI()
def get_embedding(text: str, model="text-embedding-3-large"):
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
# Exemple : transformer un chunk de document en vecteur
chunk = "Le RAG combine recherche et génération pour améliorer la fiabilité des LLM."
vector = get_embedding(chunk)
print(f"Dimension du vecteur : {len(vector)}") # 3072 pour text-embedding-3-largeÉtape 2 : Retrieval (recherche à la volée)
À chaque requête utilisateur, le système :
- Transforme la question en embedding en utilisant le même modèle que lors de l’indexation. Il est crucial d’utiliser le même encodeur, sans quoi les vecteurs ne sont pas comparables.
- Recherche les chunks les plus similaires dans la base vectorielle. La mesure la plus courante est la similarité cosinus (plus proche de 1 = plus similaire).
- Récupère les k meilleurs chunks (généralement entre 5 et 20). On parle de
top_k. - Optionnellement, applique des reranking : un second modèle plus précis (mais plus lent) peut réordonner ces chunks pour ne garder que les plus pertinents.
Bon à savoir : la recherche vectorielle trouve du sens, pas des mots-clés. La requête “comment réduire les coûts de stockage ?” peut remonter un chunk contenant “optimisation de l’espace disque” même sans les mots exacts.
Étape 3 : Génération augmentée
Le LLM reçoit un prompt structuré comme suit :
Contexte : [contenu des chunks récupérés]
Question : [question de l'utilisateur]
Instructions : Réponds à la question en utilisant UNIQUEMENT le contexte ci-dessus.
Si le contexte ne contient pas l'information, réponds "Je ne sais pas, l'information n'est pas dans les documents fournis."
Cite tes sources entre crochets.Le modèle génère une réponse fluide, factuallement contrainte par les documents, et peut référencer explicitement les chunks utilisés.
4. Les composants d’une architecture RAG
Un système RAG complet en 2026 repose sur plusieurs briques techniques, dont le choix dépend des contraintes de coût, de confidentialité et de performance.
4.1 — Modèle d’embeddings (l’encodeur)
| Modèle | Dimensions | Coût (API) | Open source | Meilleur pour |
|---|---|---|---|---|
| text-embedding-3-large (OpenAI) | 3072 | $0,13/M tokens | Non | Qualité maximale |
| voyage-2 (Voyage AI) | 1024 | $0,12/M tokens | Non | Documents longs |
| gte-Qwen2-7B-instruct | 4096 | Gratuit (local) | Oui | Confidentialité |
| cohere-embed-v3 | 1024 | $0,11/M tokens | Non | Multilingue |
4.2 — Bases vectorielles (vecteur databases)
- Pinecone : service managé, très rapide, idéal pour commencer. Gratuit pour 100k vecteurs.
- Milvus / Zilliz : open source, support hybride vectoriel + scalaire, lourde mais puissante.
- Qdrant : open source, bon équilibre performance/simplicité, API agréable.
- pgvector : extension PostgreSQL. Parfait si on a déjà une base Postgres.
- Chroma : légère, en mémoire, pour prototypes et petits volumes.
4.3 — Framework d’orchestration
LangChain reste le plus populaire (Python et TypeScript), mais sa courbe d’apprentissage est raide. LlamaIndex (ex-GPT Index) est spécialisé RAG, plus intuitif pour l’indexation. Haystack (deepset) est robuste et historique, particulièrement adapté aux pipelines de production.
Recommandation 2026 : pour une première expérience, utiliser LlamaIndex + Chroma + OpenAI embeddings. Pour la production volumique, LangChain + Qdrant + Voyage AI.
5. Cas d’usage concrets en entreprise
Le RAG n’est pas une expérience de laboratoire : il transforme déjà des processus métier.
5.1 — Chatbot interne sur la documentation technique
Une entreprise de logiciel dispose de milliers de pages de documentation interne (API, procédures, FAQ). Un chatbot RAG permet aux nouveaux développeurs de poser des questions en langage naturel et d’obtenir des réponses précises avec renvoi à la section concernée. Temps de réponse réduit de 70 %, selon une étude de Atlassian (2025) .
5.2 — Assistant juridique pour la conformité
Un service juridique doit consulter en permanence une base de textes de loi et de règlements internes. Le RAG permet de poser des questions factuelles (“Quel est le délai de conservation des données personnelles selon l’article 5 du RGPD ?”) et d’obtenir la citation exacte de l’article. Le LLM ne fait qu’interpréter — il n’invente pas la loi.
5.3 — Veille concurrentielle automatisée
Un analyste marketing collecte chaque semaine des centaines de rapports, communiqués de presse et articles. Un pipeline RAG indexe ces documents. L’analyste peut alors demander : “Quels arguments de vente concurrents sont apparus sur le marché européen au cours des 30 derniers jours ?” Le système cherche dans les documents récents et synthétise une réponse sourcée.
5.4 — Support client augmenté
Un service client reçoit des emails redondants. Le RAG indexe la base de connaissances (articles, procédures). L’agent copie-colle l’email du client ; le système suggère une réponse personnalisée en piochant dans la doc et en citant ses sources. Gain de temps estimé : 30 à 40 secondes par ticket, selon Zendesk (2026) .
6. RAG vs fine-tuning : comment choisir ?
Un classique des discussions techniques. Plutôt que de les opposer, il faut les voir comme complémentaires.
| Critère | RAG | Fine-tuning |
|---|---|---|
| Mise à jour des connaissances | Immédiate, par ajout d’un document | Lourde, car elle suppose un réentraînement |
| Données de très grande taille | Adapté à des millions de documents | Coûteux, avec une limite pratique autour de 10 000 exemples |
| Réduction des hallucinations | Forte, car le modèle est contraint par les sources | Plus faible, car le modèle peut toujours inventer |
| Adaptation du ton ou du style | Limitée, surtout par le prompt | Très efficace |
| Apprentissage de compétences | Peu adapté | Idéal |
| Coût à l’usage | Plus élevé, recherche + LLM | Plus faible, LLM seul |
| Confidentialité | Bonne, documents séparés du LLM | Variable, données intégrées dans l’entraînement |
À retenir : utilisez le RAG pour des questions factuelles sur une base de connaissances volatile. Utilisez le fine-tuning pour adapter le comportement, le style ou la structure des réponses d’un LLM. La combinaison des deux (RAG + fine-tuning sur le LLM d’exécution) donne les meilleurs résultats.
7. Guide pratique pour déployer un RAG
Voici les étapes concrètes pour construire un RAG fonctionnel en 2026.
Étape 1 — Préparer vos documents
Nettoyez, normalisez, structurez. Le RAG n’est pas une baguette magique : des documents mal formatés (scans non OCRisés, tableaux complexes, markdown incohérent) produiront des chunks inexploitables.
Étape 2 — Choisir la taille des chunks
Une règle empirique : entre 300 et 800 tokens pour la plupart des usages. Testez avec votre corpus. Trop petit → perte de cohérence. Trop grand → bruit et dépassement du contexte.
Étape 3 — Implémenter l’indexation et le retrieval
Avec LlamaIndex, l’indexation tient en quelques lignes :
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
# Charger des documents depuis un dossier
documents = SimpleDirectoryReader("mes_documents/").load_data()
# Découpage automatique + embeddings + stockage dans une base en mémoire
index = VectorStoreIndex.from_documents(documents)Étape 4 — Ajouter un reranking (optionnel mais conseillé)
Le top_k simple ramène parfois des chunks pertinents mais mal classés. Un reranker (comme cohere-rerank-v3 ou bge-reranker-large) corrige ce problème. Il est plus lent, donc appliqué uniquement sur le top_k initial (ex: on récupère 20 chunks, on reranke pour n’en garder que 5).
Étape 5 — Interroger avec un LLM
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("Quelle est la politique de confidentialité concernant les données clients ?")
print(response)
print(f"Sources : {response.source_nodes}")Étape 6 — Évaluer et itérer
Les performances d’un RAG se mesurent. Utilisez RAGAS (open source) pour évaluer la fidélité contextuelle, la pertinence de la réponse et l’absence d’hallucination sur un jeu de test.
8. Les principaux défis et leurs solutions
Aucune technologie n’est parfaite. Le RAG a ses fragilités.
Défi n°1 : la qualité des documents
Un document obsolète, contradictoire ou mal rédigé pollue les résultats. Solution : mettre en place un pipeline de validation des documents avant indexation (score de qualité, métadonnées de date et d’auteur). Ajouter un filtre temporel pour ne considérer que les documents des 6 derniers mois.
Défi n°2 : le bruit informationnel
La recherche vectorielle peut remonter des passages thématiquement proches mais non pertinents pour la question précise. Solution : utiliser la recherche hybride (vectorielle + mots-clés BM25) et le reranking.
Défi n°3 : la latence
Un RAG ajoute le temps de retrieval (souvent 200-500 ms) à celui du LLM (2-5 secondes). Solution : mettre en cache les questions fréquentes, optimiser l’index vectoriel, utiliser des LLM plus rapides (Gemini 2.5 Flash ou GPT-4o-mini) pour les cas non critiques.
Défi n°4 : les questions multi-sauts
Parfois, la réponse nécessite de combiner des informations de chunks qui ne sont pas directement liés (“Quel est le salaire moyen des ingénieurs data dans les entreprises qui utilisent le RAG ?”). Solution : architectures avancées comme RAPTOR ou self-RAG (voir section suivante).
Chiffre clé : selon Arize AI (2026) , 23 % des échecs d’un pipeline RAG proviennent d’un chunking inadapté, 31 % d’un embedding médiocre, et 46 % d’une question complexe qui nécessiterait une stratégie de retrieval plus fine.
9. Tendances 2026 : RAPTOR, self-RAG, agents et multimodal
Le RAG classique évolue rapidement. Voici les innovations majeures de 2026.
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)
Plutôt que de découper les documents en chunks plats, RAPTOR construit une arborescence hiérarchique : les chunks sont regroupés, résumés, puis ces résumés sont regroupés, etc. Pour une question large, le système commence par chercher dans les résumés de haut niveau avant de plonger dans les détails. Résultat : meilleure compréhension du contexte global. Implémenté dans LlamaIndex depuis fin 2025.
Self-RAG (Self-Reflective Retrieval-Augmented Generation)
Le LLM ne se contente pas de générer : il apprend à décider s’il a besoin de chercher, quand chercher, et si la réponse trouvée est suffisante. Un modèle est finetuné pour produire des “réflexions” intermédiaires (retrieval tokens) qui contrôlent le pipeline. Selon les auteurs (Princeton, 2025), le self-RAG améliore la factualité de 15 à 30 % par rapport au RAG standard.
Agents RAG (RAG agentique)
Un agent RAG ne fait pas qu’une seule recherche. Il peut itérer : poser une première question, analyser la réponse, puis décider de reformuler, de chercher dans une autre source, ou d’appeler un outil externe (calculatrice, API). C’est la direction prise par LangGraph et AutoGen. Les entreprises l’utilisent pour des tâches de reporting complexes nécessitant plusieurs allers-retours avec la base documentaire.
RAG multimodal
Le RAG n’est plus limité au texte. Des modèles comme GPT-4o ou Gemini 2.5 Pro acceptent des images, de l’audio, de la vidéo. On peut donc indexer non seulement des documents textuels, mais aussi des schémas, des graphiques ou des enregistrements. Une question sur un organigramme ou une infographie déclenchera la recherche du document image pertinent, puis le LLM le décrira. Kapa.ai (startup 2025) propose une API RAG multimodal spécialisée pour les manuels techniques avec schémas.
Revenir au guide complet
Cet article fait partie du guide complet sur l’IA générative en entreprise qui couvre l’ensemble des concepts, outils et applications liés à ce domaine.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
FAQ
Qu'est-ce que le RAG (Retrieval-Augmented Generation) ?
Le RAG est une architecture d'IA générative qui combine un système de recherche d'informations (retrieval) avec un modèle de langage (LLM). Avant de générer une réponse, le système va chercher dans une base de connaissances (documents internes, base vectorielle) les passages pertinents, puis les fournit au LLM comme contexte. Cette approche réduit considérablement les hallucinations et permet de répondre à partir de données actualisées ou propriétaires.
Quelle est la différence entre RAG et fine-tuning ?
Le RAG et le fine-tuning sont deux approches complémentaires. Le fine-tuning consiste à réentraîner partiellement un LLM sur un corpus spécifique pour modifier ses comportements ou son style. Le RAG, lui, ne modifie pas le modèle : il lui fournit dynamiquement des informations contextuelles au moment de l'inférence. Le RAG est plus adapté pour des données qui évoluent fréquemment (veille, FAQ, bases documentaires), tandis que le fine-tuning convient pour des besoins de ton ou de format très spécifiques.
Comment mettre en place un système RAG en entreprise ?
La mise en place d'un RAG suit quatre grandes étapes : 1) préparation des documents (découpage en chunks), 2) génération des embeddings via un modèle comme text-embedding-3-large, 3) stockage dans une base vectorielle (Pinecone, Milvus, pgvector), 4) création du pipeline de retrieval (recherche de similarité) couplé à un LLM. Des plateformes comme LlamaIndex, LangChain ou Haystack simplifient considérablement l'orchestration. Le choix du LLM d'exécution (GPT-4o, Gemini 2.5 Pro, Claude 4) influence aussi la qualité finale.
Quels sont les avantages du RAG par rapport à un LLM classique ?
Le RAG offre trois avantages majeurs : la réduction des hallucinations (le modèle s'appuie sur des faits extraits), l'accès à des données actualisées ou privées sans réentraînement, et la traçabilité (les sources ayant servi à la réponse peuvent être citées). Pour les entreprises, cela se traduit par des chatbots internes fiables, une recherche documentaire augmentée, et la possibilité de faire de la veille concurrentielle en continu.
Quels sont les principaux défis du RAG ?
Les défis incluent la qualité de la base de connaissances (données mal structurées ou obsolètes dégradent les résultats), le paramétrage de la recherche (trop de chunks → bruit, pas assez → informations manquantes), la latence (recherche + génération ralentit la réponse), et le coût (embeddings + LLM + base vectorielle). Des avancées comme le RAPTOR (structuration hiérarchique) ou le self-RAG (auto-vérification par le LLM) améliorent ces points.
Quels outils open source pour construire un RAG ?
Les outils open source les plus utilisés en 2026 sont : LangChain (orchestration, Python/JS), LlamaIndex (spécialisé RAG, très riche), Haystack (robuste, historiquement pionnier), Chroma (base vectorielle légère), Qdrant (base vectorielle performante), et pour les embeddings, sentence-transformers ou les API OpenAI. Des frameworks comme RAGFlow ou AnythingLLM proposent des interfaces no-code pour un déploiement rapide.
Le RAG est-il compatible avec des LLM locaux ?
Oui, tout à fait. Le RAG peut fonctionner avec des modèles open source comme Llama 3 (400B), Mistral Large 2, ou Command R (Cohere) exécutés localement. La partie retrieval reste inchangée ; seul le LLM de génération change. C'est une option privilégiée par les entreprises soucieuses de confidentialité des données, car aucun document ne quitte l'infrastructure. Les performances dépendent alors du LLM local choisi et du hardware disponible.
Comment évaluer la qualité d'un pipeline RAG ?
L'évaluation d'un RAG combine des métriques classiques de recherche (rappel@k, précision@k) et des métriques de génération (exactitude factuelle, pertinence, non-hallucination). Des frameworks comme RAGAS, ARES ou TruLens permettent de mesurer automatiquement ces aspects. Il est recommandé de constituer un jeu de test de questions/réponses avec sources attendues pour valider les évolutions du pipeline.
Sources
- Lewis, P. et al. (2020) – Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Meta AI / arXiv:2005.11401)
- Gartner (janvier 2026) – Hype Cycle for Artificial Intelligence, 2026 (ID G00789122)
- Contextual AI (septembre 2025) – Benchmarking Hallucination Rates in Production RAG Systems
- Asai, A. et al. (Princeton, 2025) – Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- Sarthi, P. et al. (Stanford, 2025) – RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- Arize AI (février 2026) – State of RAG in Production 2026
- Zendesk / Atlassian (études de cas internes, 2025-2026)
- McKinsey Global Institute (avril 2026) – The generative AI adoption report
Article mis à jour en mai 2026. Les prix et performances des modèles évoluent rapidement ; consultez les pages officielles des fournisseurs pour les données les plus récentes.