Le Data Engineering industrialise la donnée : il transforme des sources hétérogènes en jeux de données fiables, traçables et exploitables pour l’analytique, le produit et l’IA.
Le Data Engineering se situe au croisement de l’ingénierie logicielle, de l’exploitation, du cloud, de la modélisation analytique et de la gouvernance. C’est la couche qui rend la donnée fiable dans le temps, et pas seulement disponible à un instant donné. Si vous voulez replacer ce sujet dans une vision plus large des fondamentaux de la donnée, vous pouvez aussi consulter notre guide Data Science : méthodes, outils et rôle dans l’exploitation des données ainsi que notre panorama Big Data : définition, architecture, outils et usages.
Le Data Engineering désigne l’ensemble des pratiques, architectures et outils qui permettent de collecter, fiabiliser, transformer, documenter et servir des données de manière industrielle, afin qu’elles soient utilisables par le reporting, l’analytique, les produits numériques et les systèmes d’IA.
L’objectif n’est pas de “déplacer des données” pour qu’elles existent quelque part, mais de garantir un résultat exploitable dans le temps : définitions stables, fraicheur mesurée, qualité contrôlée, traçabilité claire, droits d’accès corrects, et coûts sous contrôle.
Le rôle a changé parce que les usages ont changé. Un pipeline “qui tourne” ne suffit plus : la donnée doit être fiable (sinon les décisions et les modèles IA se trompent), traçable (sinon personne ne peut expliquer une métrique), sécurisée (sinon le risque explose), et opérable (sinon les équipes passent leur temps à “réparer” au lieu d’améliorer).
Cette évolution est visible dans tous les environnements modernes : plateformes analytiques, produits SaaS, e-commerce, finance, logistique, marketing, applications temps réel et désormais IA générative. Là où l’on parlait autrefois surtout d’ETL, on parle désormais de pipelines industrialisés, de modèles sémantiques, de data contracts, de catalogues, d’observabilité et de gouvernance. Le périmètre s’est donc élargi, non par effet de mode, mais parce que la donnée est devenue un actif de production.
Autrement dit, le Data Engineering ne se résume pas à une couche technique cachée derrière des dashboards. Il conditionne la confiance dans les indicateurs, la reproductibilité des analyses, la qualité des features utilisées par le machine learning, et même la pertinence des systèmes RAG lorsqu’ils s’appuient sur des documents ou des corpus internes. Pour approfondir la préparation concrète des flux, vous pouvez aussi consulter notre article sur les pipelines de données, ETL, ELT et orchestration des flux.
Le Data Engineering est à la donnée ce que l’ingénierie logicielle est à une application : il transforme une accumulation de scripts et d’outils en un système exploitable, testable, évolutif et gouverné.
Quand une organisation dit qu’elle veut “mieux exploiter ses données”, elle parle souvent d’analytique ou d’IA. Mais en pratique, cette ambition dépend d’abord d’une capacité plus discrète : rendre la donnée disponible de manière fiable, compréhensible et gouvernable. C’est précisément le rôle du Data Engineering.
Trois dynamiques expliquent la centralité du Data Engineering : (1) la multiplication des sources et des formats, (2) l’exigence de fraicheur (données disponibles plus vite), (3) la pression IA qui rend la gouvernance et la qualité non négociables.
La plupart des organisations combinent aujourd’hui des bases transactionnelles (produit), des CRM, des outils marketing, de la finance, du support, des logs, et des événements temps réel. Cette diversité crée des problèmes structurels : identifiants incohérents, schémas instables, règles métier implicites, historiques partiels, et difficultés à reproduire un calcul dans le temps. Le Data Engineering apporte une discipline : capturer, normaliser, historiser, et produire des datasets “consommables” avec des contrats stables.
Dans les faits, cette complexité est devenue la norme. Même une entreprise de taille intermédiaire manipule souvent des outils SaaS multiples, des exports de fichiers, des APIs tierces, des données événementielles et des historiques imparfaits. Cela explique pourquoi des sujets en apparence techniques, comme les différences entre API et webservices ou la manière de prétraiter et inspecter les données avec SQL, ont un impact direct sur la fiabilité de toute la chaine décisionnelle.
Une annonce IBM cite une enquête Gartner : 63% des organisations n’ont pas, ou ne savent pas si elles ont, les bonnes pratiques de gestion de données pour l’IA. Cette statistique illustre un point simple : l’IA pousse la donnée hors du périmètre BI traditionnel, vers des usages plus sensibles (documents, contenus, données non structurées, traces), où la gouvernance et la traçabilité deviennent indispensables. [Source]
Cette pression s’observe tout particulièrement dans les projets d’IA générative. Les entreprises veulent connecter des assistants, des moteurs de recherche interne, des copilot et des workflows automatisés à leurs contenus. Mais dès que les données sont incomplètes, mal versionnées, redondantes ou mal gouvernées, le système perd en pertinence, en sécurité et en confiance. C’est pourquoi le Data Engineering devient une condition d’entrée pour beaucoup de cas d’usage IA, et pas seulement un sujet d’optimisation secondaire.
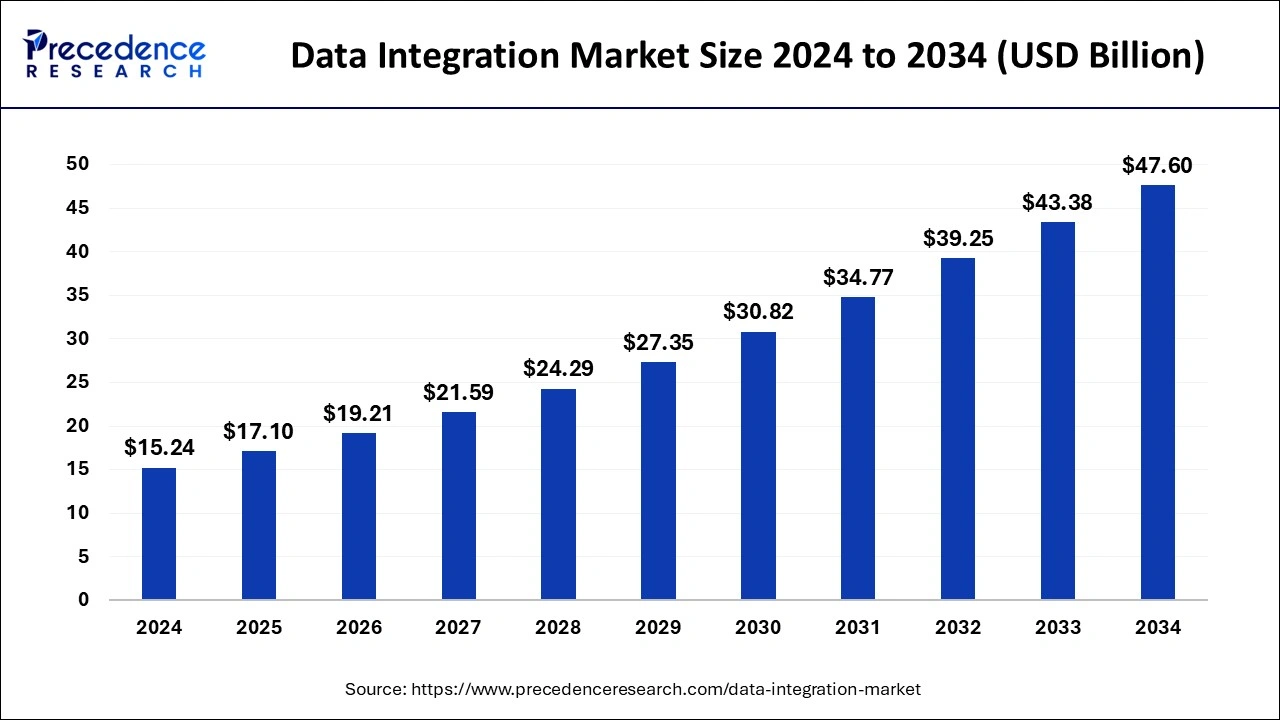
Les marchés adjacents (intégration, entrepôts cloud) donnent une lecture macro. Precedence Research indique que le marché mondial de l’intégration de données est évalué à 17,10 Md$ en 2025 et devrait passer à 19,21 Md$ en 2026, avec une estimation à 51,82 Md$ d’ici 2035 (CAGR 11,72% sur 2026–2035). [Source]
Mordor Intelligence affiche publiquement une estimation du marché “cloud data warehouse” à 14,94 Md$ en 2026 et une projection à 49,12 Md$ d’ici 2031 (CAGR 26,86% sur 2026–2031). [Source]
IndustryARC publie une projection différente (périmètre et méthodologie potentiellement distincts) : “Cloud Data Warehouse Market” à 39,1 Md$ d’ici 2026 après une croissance à 31,4% de CAGR sur 2021–2026. [Source]
Des rapports différents peuvent produire des valeurs éloignées sans que l’un soit “faux” : les écarts viennent des définitions de marché, des segments inclus, et des régions. L’intérêt opérationnel est de constater une tendance durable : consolidation des outils, migration cloud, et montée de l’exigence de gouvernance portée par l’IA.
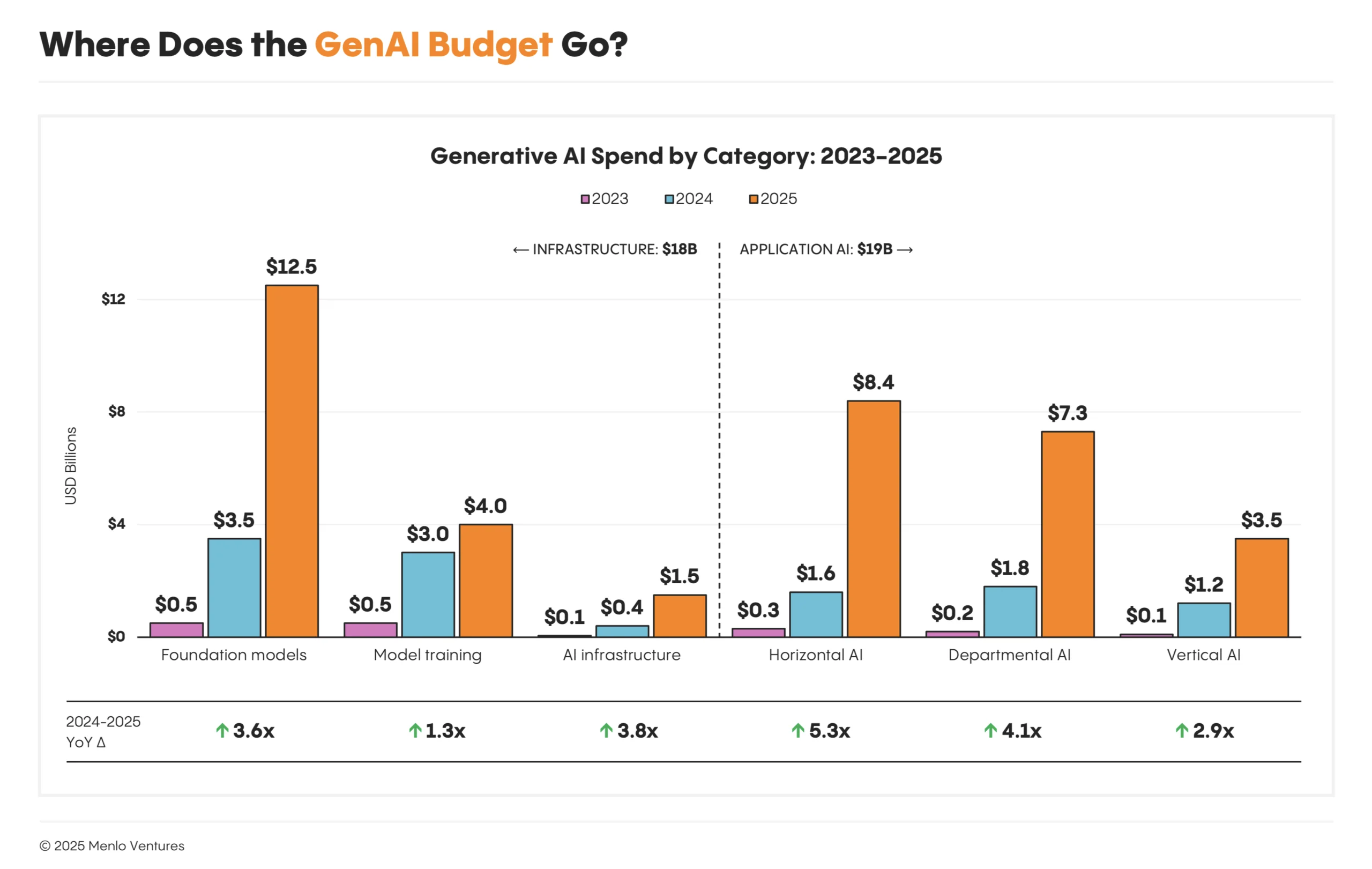
Menlo Ventures indique que les entreprises ont dépensé 37 Md$ en IA générative en 2025, contre 11,5 Md$ en 2024 (x3,2 sur un an). Le rapport mentionne également que 76% des cas d’usage IA sont achetés plutôt que construits, et que 47% des “AI deals” vont en production (vs 25% pour le SaaS traditionnel). Dans ce contexte, la capacité à intégrer rapidement des données fiables, gouvernées et observables devient un avantage concurrentiel. [Source]
Cette évolution ne signifie pas seulement plus d’outils. Elle signifie aussi plus de dépendance à des flux internes propres, à des identifiants stables, à des droits d’accès correctement appliqués et à des mécanismes de mise à jour pilotables. Dans ce contexte, un environnement data mal conçu devient rapidement un frein à l’expérimentation, à la conformité et au passage en production.
Le Data Engineer conçoit, assemble, sécurise et industrialise les flux de données qui alimentent les tableaux de bord, les analyses métiers, les applications data et les projets d’intelligence artificielle. Là où le Data Scientist cherche à modéliser et prédire, là où l’analyste interprète et aide à la décision, le Data Engineer construit l’infrastructure invisible qui permet à tout le reste de fonctionner correctement.
Concrètement, son travail commence très en amont : il identifie les sources, récupère la donnée depuis des API, des applications SaaS, des bases transactionnelles, des fichiers, des événements temps réel ou des outils métiers, puis l’achemine vers des environnements de stockage et de calcul adaptés. Cette logique de circulation et de transformation est au cœur des pipelines de données ETL, ELT et d’orchestration des flux, qui constituent l’une des briques les plus importantes d’une architecture data moderne.
Une fois la donnée collectée, le Data Engineer la nettoie, la structure, la versionne, l’enrichit et la rend interrogeable. Il définit aussi les règles de qualité, de fraîcheur et de fiabilité. Dans de nombreuses organisations, il devient le garant d’une promesse simple mais difficile à tenir : proposer la bonne donnée, au bon format, au bon moment, à la bonne personne.
Le Data Engineer collabore avec les équipes produit, analytics, métier, sécurité, IT, cloud, conformité et gouvernance. Il intervient souvent entre le monde opérationnel et le monde analytique. Cette position charnière explique pourquoi il doit à la fois comprendre les enjeux business, les contraintes techniques et les exigences de long terme.
| Rôle | Mission principale | Livrables typiques | Question clé |
|---|---|---|---|
| Data Engineer | Construire et fiabiliser les flux, plateformes et modèles de données | Pipelines, tables, jobs, monitoring, documentation | Comment rendre la donnée disponible et fiable ? |
| Data Analyst | Analyser, visualiser et interpréter la donnée | Dashboards, rapports, analyses, recommandations | Que disent les données sur l’activité ? |
| Data Scientist | Créer des modèles statistiques ou prédictifs | Modèles, notebooks, scores, expérimentations | Que peut-on prévoir ou optimiser ? |
| Analytics Engineer | Modéliser la donnée pour l’analyse métier | Mart analytiques, métriques, logique sémantique | Comment rendre la donnée lisible par le métier ? |
Le Data Engineering moderne ne se limite plus à un entrepôt de données et à quelques scripts planifiés la nuit. Les organisations doivent gérer simultanément des volumes croissants, des rythmes de mise à jour très différents, des attentes métiers de plus en plus fortes et des contraintes de gouvernance qui s’intensifient. C’est dans ce contexte qu’ont émergé des architectures plus modulaires, plus résilientes et plus adaptées à la diversité des cas d’usage.
Le traitement batch demeure la base de nombreuses chaînes décisionnelles. Il reste parfaitement adapté aux consolidations quotidiennes, à la production d’indicateurs, aux réconciliations, aux contrôles et aux historiques. Sa force est sa stabilité : il est plus simple à superviser, souvent plus économique, et plus lisible pour les équipes métiers.
Dans beaucoup d’organisations, la meilleure stratégie ne consiste pas à remplacer le batch, mais à le moderniser : meilleure orchestration, tests plus systématiques, reprise sur incident, documentation plus fine et meilleure séparation entre couches brutes, préparées et métier. Sur ce point, la lecture du guide dédié aux pipelines de données ETL, ELT et orchestration des flux permet d’aller plus loin.
Le streaming devient pertinent lorsqu’une organisation doit réagir rapidement à des événements : détection d’anomalies, suivi logistique, alerting, observabilité produit, personnalisation, suivi opérationnel ou actualisation très fréquente d’indicateurs. Mais le temps réel n’est pas une fin en soi. Il a un coût de complexité, d’exploitation et de supervision qu’il faut justifier par un besoin réel.
Une architecture moderne combine donc souvent plusieurs rythmes de traitement : batch pour les consolidations, micro-batch pour certains flux quasi temps réel, et streaming pour les cas critiques. L’enjeu du Data Engineer est de savoir où placer le curseur.
L’approche lakehouse cherche à réconcilier deux mondes longtemps séparés : la souplesse des data lakes et la rigueur analytique des entrepôts. Elle permet de stocker des données variées tout en gardant des garanties plus fortes sur la structure, la qualité, la performance de lecture et la gouvernance. Cette logique intéresse particulièrement les organisations qui doivent alimenter en parallèle la BI, la science des données et les usages d’IA.
Le choix des briques techniques dépend du contexte, mais la tendance de fond est claire : les équipes cherchent des architectures capables d’accepter des sources hétérogènes sans renoncer à la traçabilité ni à la lisibilité. Pour comprendre les environnements analytiques à grande échelle, il est aussi utile de consulter l’article consacré à BigQuery et aux plateformes de traitement massif de données.
Plus une architecture se complexifie, plus l’orchestration devient centrale. Elle permet de planifier les traitements, d’enchaîner les dépendances, de relancer proprement les jobs, de suivre les exécutions, d’alerter en cas d’échec et de rendre la chaîne globale compréhensible. Une architecture sans orchestration claire devient vite fragile, coûteuse à maintenir et difficile à faire évoluer.
Les outils du Data Engineering ne doivent pas être choisis comme un simple inventaire technologique. Leur rôle est de former une chaîne cohérente, capable de couvrir l’ingestion, le stockage, la transformation, l’exposition, la supervision et la gouvernance. Une stack efficace n’est pas forcément la plus riche : c’est celle qui reste lisible, maintenable et adaptée au niveau de maturité de l’organisation.
Tout commence par la capacité à récupérer la donnée. Cela passe par des connecteurs applicatifs, des exports planifiés, des API, des événements, des réplications ou des synchronisations incrémentales. Cette brique est souvent sous-estimée alors qu’elle conditionne la fraîcheur, la complétude et la stabilité de tout l’écosystème data.
Dans les environnements très connectés, la maîtrise des interfaces est essentielle. C’est pourquoi il peut être utile de compléter cette lecture par le tutoriel Webservices vs API : quelles différences pour l’intégration de solutions, qui aide à mieux comprendre la nature des échanges entre systèmes.
Une fois la donnée collectée, il faut la transformer. Cela implique des nettoyages, harmonisations, jointures, agrégations, contrôles, standardisations et enrichissements. C’est à ce moment que la donnée brute commence à prendre une forme exploitable par les métiers. La qualité du modèle construit ici influence directement la qualité des analyses futures.
Le stockage ne se résume pas à “garder” la donnée. Il faut choisir les formats, la granularité, les partitions, les politiques d’historisation et les niveaux d’accès. Selon les besoins, on s’oriente vers un data warehouse, un data lake, un lakehouse ou une combinaison de plusieurs environnements. Dans les contextes analytiques intensifs, la comparaison entre plateformes peut fortement impacter les performances, les coûts et la gouvernance.
Pour approfondir cette dimension, la page BigQuery et autres plateformes de traitement massif de données constitue un bon prolongement.
Une plateforme data utile est une plateforme observable. Il faut savoir si les données sont arrivées, si elles ont été transformées correctement, si les volumes sont cohérents, si certaines colonnes dérivent, si les temps d’exécution dérapent et si les tables exposées sont encore alignées avec les usages métiers. Sans cette couche, la confiance s’érode très vite.
Cette exigence de fiabilité rejoint d’ailleurs les bonnes pratiques décrites dans Construire un pipeline de données efficace : bonnes pratiques et outils, qui peut servir de satellite naturel à cette page pilier.
Enfin, la donnée doit pouvoir être consommée. Cela signifie qu’elle doit être compréhensible par les analystes, interrogeable efficacement, documentée et suffisamment stable pour soutenir les usages du quotidien. À cet égard, la maîtrise du SQL reste un fondamental très structurant pour les équipes. Le tutoriel Prétraitement et inspection des données avec SQL complète logiquement le parcours.
Une bonne architecture de Data Engineering n’est pas seulement performante sur le papier : elle reste compréhensible, documentée, testable et évolutive. Trop d’organisations créent des pipelines qui fonctionnent “pour l’instant”, mais qui deviennent très vite difficiles à maintenir à mesure que les cas d’usage se multiplient. Les bonnes pratiques servent précisément à éviter cet effet d’empilement.
Un pipeline ne devrait pas être vu comme un simple script technique. Il a des utilisateurs, des attentes de disponibilité, des critères de qualité, une fréquence de mise à jour, une documentation et un niveau de criticité. Le considérer comme un produit aide à clarifier sa gouvernance, son cycle de vie et sa dette potentielle.
Les contrats de données formalisent les engagements autour d’un flux ou d’une table : schéma attendu, règles métier, fréquence d’actualisation, niveaux de qualité, propriétaire, conditions d’usage. Ils réduisent les surprises et améliorent la coordination entre producteurs et consommateurs.
Il ne suffit pas qu’un job “s’exécute” pour qu’il soit fiable. Il faut aussi vérifier la présence des données, la conformité du schéma, la cohérence de certains indicateurs, la non-régression des volumes et la stabilité de certains calculs. Plus les tests sont pensés tôt, plus la plateforme gagne en robustesse.
Les données arrivent parfois en retard, certaines sources changent, des erreurs se glissent dans les traitements, des historiques doivent être rejoués. Une bonne architecture prévoit ce type de situations. Elle distingue les données brutes des couches transformées, historise intelligemment et permet de relancer proprement sans casser tout l’écosystème.
Une plateforme devient fragile lorsqu’elle repose sur la mémoire de deux ou trois personnes. La documentation des tables, des champs, des transformations, des dépendances et des propriétaires n’est pas un “plus” : c’est une composante opérationnelle. Elle améliore aussi l’expérience des équipes métiers et accélère la diffusion du self-service data.
Toutes les organisations n’ont pas besoin de la même architecture. Le bon choix dépend du volume, de la variété des sources, du niveau d’exigence en fraîcheur, des contraintes réglementaires et des usages finaux. Ce tableau donne un repère simple pour comparer les grandes approches.
| Approche | Quand l’utiliser | Forces | Limites |
|---|---|---|---|
| Batch classique | Reporting, consolidation, historique, BI quotidienne | Stabilité, lisibilité, coûts maîtrisés | Latence plus élevée |
| Micro-batch | Actualisation fréquente sans vraie contrainte temps réel | Bon compromis performance / complexité | Moins instantané que le streaming |
| Streaming | Alerting, monitoring, événements, personnalisation | Réactivité, données fraîches, usages critiques | Exploitation plus complexe |
| Data warehouse | Analyse métier structurée, KPIs, gouvernance forte | Performance analytique, cadre clair | Moins souple pour les données très variées |
| Data lake / lakehouse | Volumes variés, IA, data science, analytique hybride | Souplesse, échelle, convergence des usages | Nécessite une gouvernance rigoureuse |
Dans les faits, les architectures les plus solides sont souvent hybrides. Elles combinent plusieurs briques pour répondre à différents besoins sans faire exploser la complexité. Le vrai sujet n’est donc pas de choisir un mot à la mode, mais de concevoir une architecture cohérente avec les usages réels de l’entreprise.
On parle souvent du Data Engineering comme d’une discipline technique, alors qu’il produit en réalité des effets très concrets sur la performance des organisations. Chaque fois qu’un indicateur est mis à jour à temps, qu’un tableau de bord inspire confiance, qu’un modèle d’IA est alimenté avec des données cohérentes ou qu’une équipe gagne du temps d’analyse, il y a presque toujours un travail de Data Engineering en amont.
Les directions métier ont besoin de chiffres cohérents, traçables et comparables dans le temps. Le rôle du Data Engineer est d’éviter la prolifération des extractions manuelles et des “versions concurrentes” de la vérité. Il crée des couches stabilisées qui servent de base commune au pilotage.
Dans les environnements numériques, les équipes produit doivent suivre les parcours, les conversions, les points de friction et les performances fonctionnelles. Cela suppose des événements correctement collectés, nettoyés et exposés. Sans pipeline fiable, l’analytics produit devient vite incomplète ou trompeuse.
Les projets d’IA reposent sur des données prêtes à l’emploi. Sans ingestion propre, sans historisation, sans versionnement et sans contrôles qualité, les modèles apprennent mal, dérivent vite ou donnent des résultats difficilement défendables. C’est particulièrement vrai dans les contextes où l’IA doit être mise en production et reliée à des processus métier. Les pages consacrées à la définition et au fonctionnement de l’intelligence artificielle et à l’IA générative en entreprise montrent d’ailleurs à quel point la qualité de la donnée conditionne l’efficacité réelle des usages.
CRM, ERP, marketing, support, finance, produit, logistique, outils RH : les organisations empilent les systèmes. Le Data Engineer a pour mission de rendre ce paysage interopérable, sans multiplier les rustines. C’est là que la compréhension des échanges inter-applicatifs, des connecteurs et des APIs devient stratégique.
Une architecture data ne vaut que si elle reste gouvernable. Plus les volumes augmentent, plus la circulation de la donnée s’intensifie, et plus la question de la responsabilité devient centrale. Qui produit la donnée ? Qui peut y accéder ? Comment savoir d’où elle vient, ce qu’elle contient, comment elle a été transformée et à quelles finalités elle peut être utilisée ?
Le Data Engineering moderne doit donc intégrer la gouvernance dès la conception, et non comme une couche ajoutée a posteriori. Cela implique une gestion fine des droits, une séparation des environnements, une traçabilité des transformations, une documentation claire et une politique rigoureuse de conservation.
Tout le monde n’a pas besoin d’accéder à tout. La bonne pratique consiste à limiter les accès selon les usages, à journaliser les actions sensibles et à protéger les zones les plus critiques. Cette logique est aussi essentielle dans les environnements collaboratifs où les métiers accèdent directement à certaines couches de données.
Savoir d’où vient une donnée et comment elle a été transformée devient indispensable dès qu’un indicateur engage une décision importante. Le lineage aide à remonter la chaîne, à auditer les transformations et à résoudre plus vite les incidents. Il est aussi très utile lorsqu’un flux change ou lorsqu’un contrôle qualité détecte une dérive.
Dès que des données personnelles, financières, contractuelles ou stratégiques circulent, les obligations montent d’un cran. Le Data Engineer doit travailler avec les équipes conformité et sécurité pour mettre en place anonymisation, pseudonymisation, cloisonnement, journalisation et règles de conservation adaptées.
Cette dimension fait écho aux enjeux plus larges abordés dans la rubrique Éthique et société, qui peut constituer un lien transverse pertinent pour renforcer le maillage sans sortir du sujet.
Le Data Engineering promet ordre, fluidité et fiabilité. Dans la pratique, il doit surtout composer avec l’imperfection du réel. Les systèmes changent, les métiers évoluent, les sources sont incomplètes, les équipes manquent parfois de temps, et les plateformes grandissent plus vite que leur documentation. Ce décalage entre ambition et terrain explique pourquoi tant de projets data peinent à passer à l’échelle.
Chaque nouvel outil ajoute un connecteur, un schéma, une logique métier, un niveau de qualité et un cycle de mise à jour différents. Cette hétérogénéité rend la standardisation difficile et alourdit la maintenance.
Un flux créé rapidement pour répondre à un besoin urgent peut rester en production pendant des années. Sans revue régulière, sans documentation ni tests, il devient une source de fragilité. La dette technique des pipelines est l’un des principaux freins à la scalabilité des plateformes data.
Le problème n’est pas toujours technologique. Il est souvent lié à la gouvernance, aux responsabilités floues, à l’absence de priorisation ou à une mauvaise coordination entre les producteurs de données et les équipes qui les exploitent.
Beaucoup d’organisations visent le temps réel parce qu’il semble moderne ou stratégique, alors qu’un bon batch bien orchestré suffit largement à leurs besoins. Chercher la sophistication trop tôt peut faire monter les coûts, augmenter les risques d’incident et détourner les équipes des vrais irritants métier.
Une plateforme data devient difficile à piloter dès lors que personne ne sait précisément quelles tables sont fiables, quels flux sont critiques, quelles dépendances existent et quels traitements peuvent être supprimés sans impact. L’enjeu n’est pas seulement d’accumuler des données, mais de maintenir un patrimoine exploitable.
Le Data Engineering continue d’évoluer rapidement. Mais au-delà des effets de mode, quelques mouvements de fond se dessinent nettement. Les entreprises cherchent désormais moins à “tout centraliser” qu’à rendre leur écosystème plus pilotable, mieux documenté et plus utile à l’échelle.
Les équipes ne veulent plus découvrir les incidents a posteriori. Elles cherchent à surveiller la fraîcheur, la complétude, les dérives de schéma, les ruptures de volume et les anomalies comportementales plus tôt, avec des signaux exploitables.
La documentation, les catalogues, les propriétaires de données, les contrats et le lineage ne sont plus vus comme des annexes théoriques. Ils deviennent des briques de fonctionnement quotidien. Ce glissement est essentiel pour soutenir la montée en charge.
Plus les organisations déploient des cas d’usage d’IA, plus elles redécouvrent un principe fondamental : un système intelligent reste dépendant de la qualité des données qui l’alimentent. Les pipelines, la préparation, la fraîcheur et la gouvernance des contenus deviennent donc encore plus stratégiques.
Certaines briques se renforcent autour des besoins décisionnels, d’autres autour du traitement massif, d’autres encore autour de l’activation ou de l’IA. Le défi des années à venir ne sera pas seulement de choisir les bons outils, mais de les faire dialoguer sans recréer des silos.
Les entreprises les plus efficaces ne sont pas forcément celles qui possèdent la stack la plus impressionnante, mais celles qui rendent leur architecture compréhensible. Cela passe par des standards de nommage, une documentation claire, des parcours d’usage et des points d’entrée bien pensés.
Non. L’ETL n’en représente qu’une partie. Le Data Engineering couvre aussi l’ingestion, l’orchestration, la modélisation, la qualité, la sécurité, la documentation, l’observabilité et la mise à disposition des données pour différents usages.
Le Data Engineering construit et fiabilise le socle technique des données. La Data Science exploite ensuite ces données pour modéliser, prédire, segmenter ou automatiser. Les deux fonctions sont complémentaires. Si vous souhaitez clarifier cette articulation, consultez aussi notre guide complet sur la Data Science.
Non. Le temps réel n’est utile que lorsqu’il répond à une vraie contrainte métier. Dans de nombreux cas, un batch ou un micro-batch bien conçu apporte un meilleur compromis entre coût, robustesse et simplicité.
Oui, très souvent. Même dans des stacks modernes, le SQL reste un langage fondamental pour transformer, contrôler et exposer la donnée. Le tutoriel Prétraitement et inspection des données avec SQL est un excellent complément à ce sujet.
Dès lors que les flux se multiplient, que plusieurs équipes consomment la même donnée, que des enjeux réglementaires existent ou que les décisions dépendent d’indicateurs critiques. Plus on tarde, plus la remise en ordre devient coûteuse.
Oui, de façon décisive. Sans données propres, stables, historisées et bien gouvernées, les projets d’IA restent fragiles. C’est pourquoi cette page s’articule naturellement avec le guide sur l’intelligence artificielle et le guide pratique de l’IA générative en entreprise.
Ces références externes servent surtout à cadrer les tendances de fond du marché, l’importance de l’intégration de données et la montée en puissance des usages analytiques et IA en entreprise.
Le Data Engineering occupe aujourd’hui une position centrale dans l’économie de la donnée. Il ne s’agit plus seulement de déplacer des fichiers ou de planifier quelques traitements nocturnes, mais de créer les conditions de fiabilité, de lisibilité et de continuité qui rendent la donnée réellement utile. Sans ce socle, les dashboards deviennent contestables, les analyses perdent en crédibilité et les projets d’IA peinent à passer du prototype à la production.
Les architectures modernes, les plateformes analytiques, les flux temps réel, les besoins métiers croissants et les exigences de gouvernance ont fait évoluer ce métier vers un rôle beaucoup plus structurant. Le Data Engineer est désormais au croisement de l’ingénierie, de l’analytics, de la conformité et de la stratégie d’entreprise.
Si vous souhaitez approfondir pas à pas, la meilleure suite logique consiste à explorer les pipelines ETL, ELT et l’orchestration des flux, puis les bonnes pratiques pour construire un pipeline de données efficace. Vous pouvez aussi replacer cette discipline dans un cadre plus large grâce à nos guides sur la Data Science, le Big Data et l’intelligence artificielle.