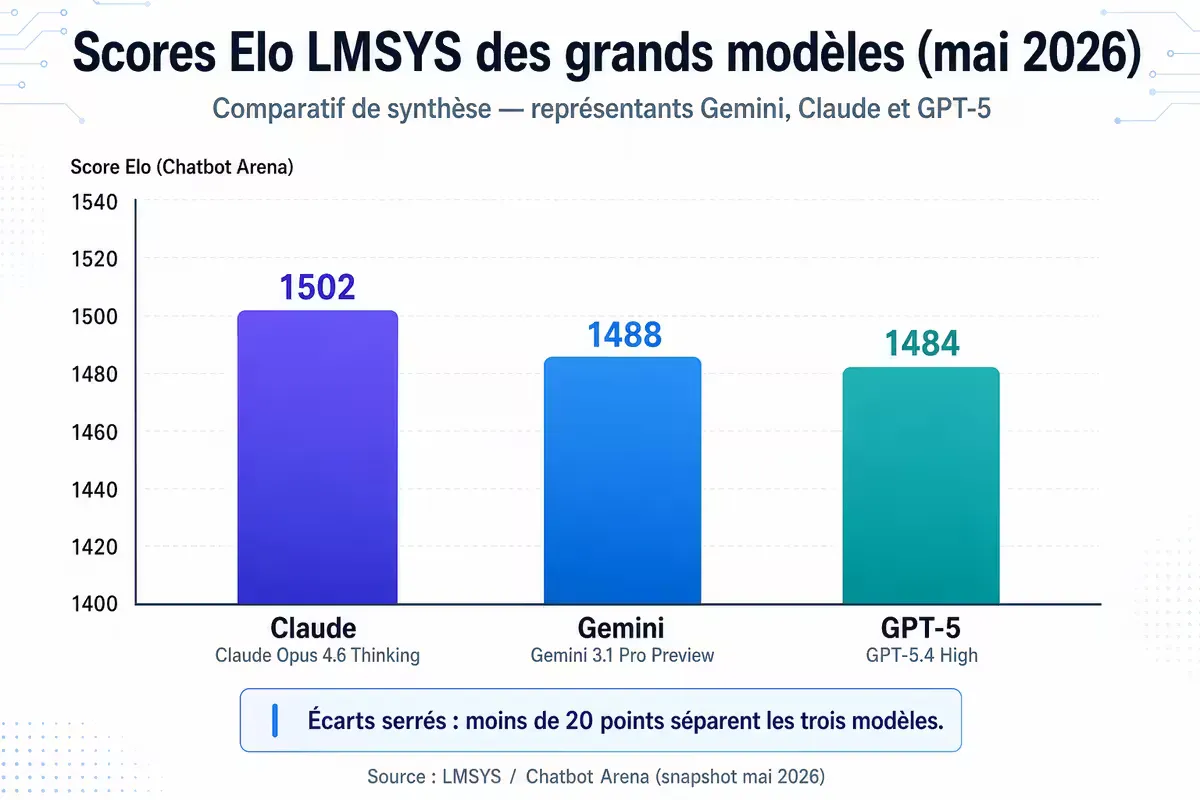
Figure — Scores Elo LMSYS (mai 2026) : Gemini 3.1 Pro , Claude 4.5 et GPT-5 .
En 2026, la question n’est plus “faut-il utiliser l’IA ?” mais “quel modèle d’IA correspond à mon usage ?” Plus d’une quarantaine de modèles de pointe se disputent le marché, chacun avec ses forces et faiblesses spécifiques .
Résumé
Ce comparatif mobilise les principaux benchmarks indépendants de 2026 : LMSYS Chatbot Arena (préférence humaine), SWE-bench Verified (capacités de codage), GPQA Diamond (raisonnement expert) et analyses de la WebDev Arena. Google Gemini 3.1 Pro excelle dans l’intégration Workspace et l’analyse multimodale. Claude 4.6 domine le développement logiciel avec plus de 70% de résolution sur SWE-bench. ChatGPT Plus conserve un excellent rapport polyvalence-prix. Des alternatives comme Meta Muse Spark (gratuit) et Perplexity Pro (recherche sourcée) offrent des propositions de valeur distinctes.
Table des matières
- Méthodologie : comment nous comparons les IA en 2026
- Gemini 3.1 Pro (Google) : l’excellence intégrée
- Claude 4.6 (Anthropic) : le roi du développement
- ChatGPT Plus (OpenAI) : le couteau suisse
- Perplexity Pro : la recherche sourcée en temps réel
- Meta Muse Spark : la rupture gratuite
- Tableau comparatif des abonnements ($20/mois)
- Comment choisir selon votre profil
- FAQ
Méthodologie : comment nous comparons les IA en 2026
Notre analyse repose exclusivement sur des benchmarks publics et indépendants, évitant les tests maison ou les démonstrations éditorialisées.
Les références utilisées
LMSYS Chatbot Arena : benchmark de référence mesurant la préférence humaine. Deux modèles répondent anonymement à une même question ; les utilisateurs désignent leur préférence sans connaître l’identité des modèles. Le score Elo qui en résulte est le meilleur indicateur de la qualité perçue .
SWE-bench Verified : référence absolue pour les capacités de codage agentique. Le modèle doit résoudre des issues GitHub réelles : localiser un bug, proposer une correction, passer les tests. Impossibilité de tricher par mémorisation .
GPQA Diamond : batteries de questions de niveau doctorat en biologie, physique et chimie, conçues pour résister aux moteurs de recherche. Mesure le raisonnement expert pur .
WebDev Arena : benchmark spécialisé dans le développement web, comparant les modèles sur des tâches HTML/CSS/React en aveugle .
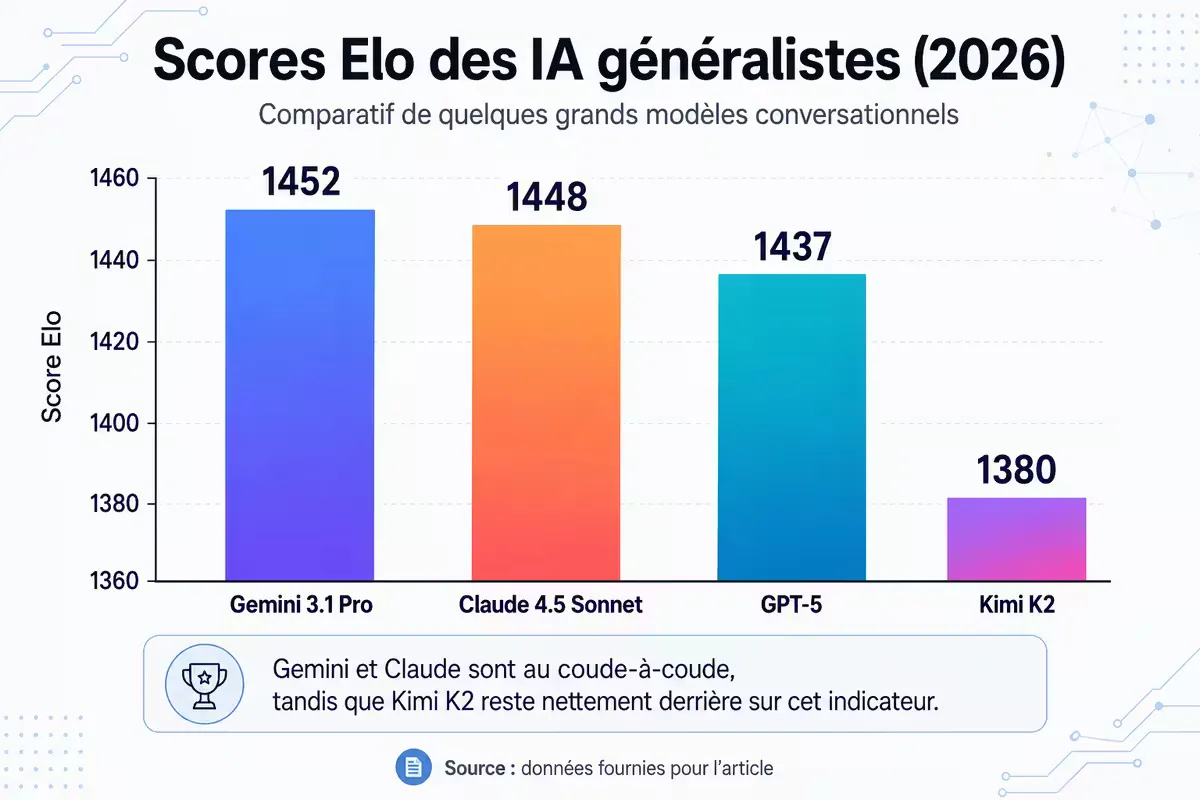
Figure — Scores Elo sur le LMSYS Chatbot Arena (mai 2026) : Gemini 3.1 Pro devance très légèrement Claude 4.5 Sonnet, avec un écart statistiquement faible .
À retenir : Les écarts entre les trois premiers modèles sont très faibles (moins de 15 points Elo). L’utilisateur moyen ne percevra pas de différence significative de qualité de réponse. Le choix doit donc se faire sur des critères fonctionnels : intégrations, outils spécifiques, coût.
Gemini 3.1 Pro (Google) : l’excellence intégrée
Gemini 3.1 Pro, sorti en février 2026, est le modèle préféré des utilisateurs sur le LMSYS Chatbot Arena avec un score Elo de 1452, devançant très légèrement Claude (1448) .
Points forts distinctifs
Intégration Workspace native : Gemini lit et synthétise vos emails Gmail, vos documents Drive, vos feuilles Sheets et vos présentations Slides sans copier-coller. Pour une organisation déjà équipée Google Workspace, la friction d’usage est quasi nulle .
Deep Research : capable de produire des rapports autonomes de 10 à 50 pages, sourcés et structurés, à partir d’une simple requête. Les utilisateurs soulignent la qualité des citations et la profondeur d’analyse .
Analyse visuelle avancée : reconnaissance d’écriture manuscrite, extraction OCR précise, interprétation de diagrammes complexes et de formules LaTeX sans perte de contexte .
Veo 3.1 illimité : les abonnés Pro ($19.99/mois) bénéficient d’une génération vidéo illimitée, un avantage unique sur le marché .
Limitations
Les performances en raisonnement pur sont très bonnes mais légèrement inférieures à GPT-5 sur GPQA Diamond (84,6 % contre 89,4 %) . L’écosystème verrouille partiellement l’utilisateur : les meilleures fonctionnalités supposent d’être chez Google.
GPQA Diamond : benchmark de questions de niveau doctorat conçues pour être “google-proof” — impossibles à résoudre par simple recherche web. Mesure la compréhension scientifique profonde.
Claude 4.6 (Anthropic) : le roi du développement
Anthropic a frappé fort en 2026. La famille Claude 4.6 occupe les quatre premières places de la WebDev Arena, un benchmark spécialisé dans le développement web. Claude Opus 4.6 atteint un score Elo de 1560, reléguant GPT-5.2 High à la cinquième place .
Performance agentique inégalée
Claude 4.5 Sonnet atteint 70,6 % de résolution sur SWE-bench Verified. Concrètement, le modèle peut recevoir la description d’un bug dans une codebase réelle, localiser le fichier problématique, proposer une correction et la valider par des tests — le tout de manière autonome .
Claude Code : terminal agentique permettant au modèle d’exécuter des commandes, lire des fichiers et itérer de manière autonome. Les développeurs rapportent des sessions où Claude travaille “pendant des heures” sur des refactorings complexes .
Fenêtre de contexte : 1 million de tokens (beta), permettant d’ingérer l’intégralité d’une codebase ou de très longs documents techniques.
Tarification
Claude Pro à $20/mois donne accès à Sonnet 4.6 (le modèle de travail quotidien). L’accès à Opus 4.7, le modèle ultime pour les tâches les plus complexes, est sévèrement limité sur ce plan — les utilisateurs intensifs devront passer par l’API .
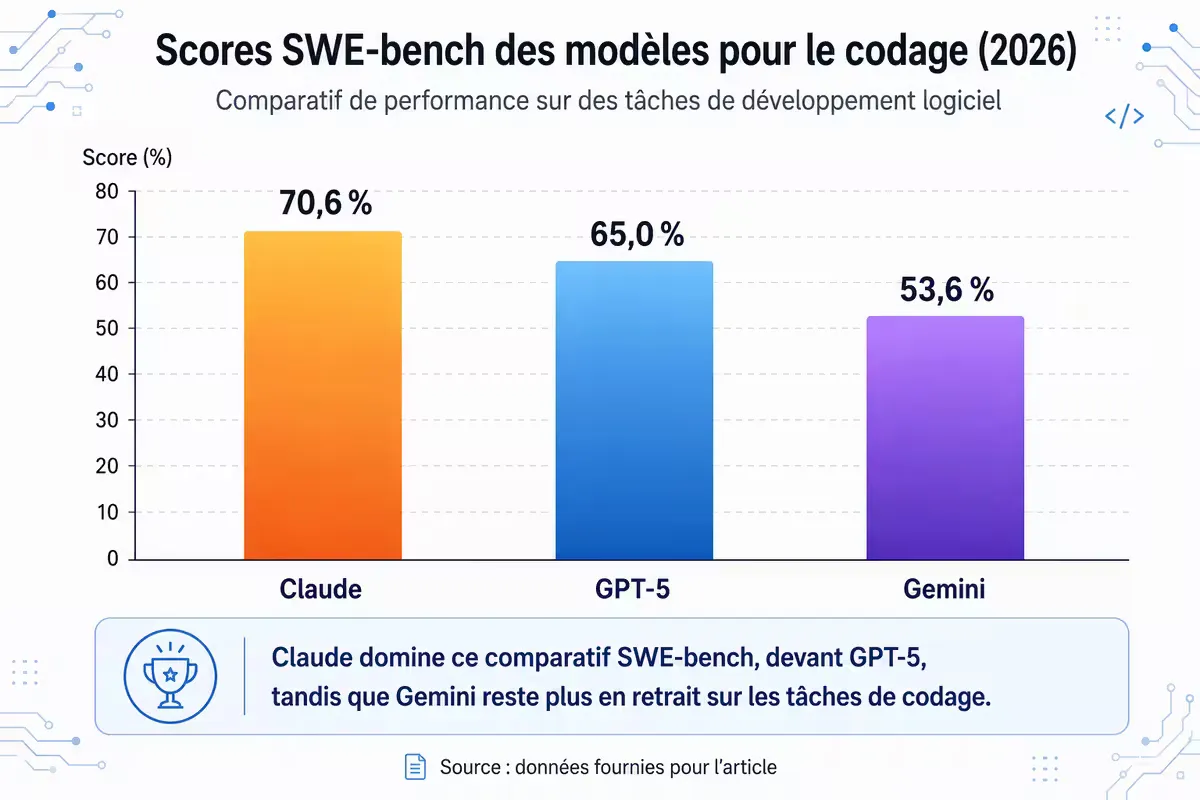
Figure — Performance sur SWE-bench Verified (mai 2026). L’écart entre Claude et ses concurrents en résolution de bugs réels est significatif .
ChatGPT Plus (OpenAI) : le couteau suisse
ChatGPT Plus reste l’option la plus polyvalente à $20/mois. OpenAI a unifié ses modèles au sein de GPT-5, un système capable d’acheminer intelligemment chaque requête vers le modèle le plus adapté .
Forces principales
Polyvalence maximale : GPT-5 excelle dans presque tous les domaines sans être le meilleur dans aucun. Pour l’utilisateur qui passe du brainstorming créatif à l’analyse de données, c’est un atout.
Écosystème riche : plus de 60 connecteurs applicatifs (Slack, GitHub, Google Drive, Salesforce, Atlassian). Les Custom GPTs permettent de créer des assistants spécialisés sans code .
Sora 1 incluse : 50 vidéos par mois générées, un ajout significatif pour les créateurs de contenu .
Mode vocal avancé : environ 1 heure par jour de conversation vocale à faible latence, utile pour la prise de notes ou la réflexion à voix haute.
Scores benchmarks
GPT-5 (high) obtient 89,4 % sur GPQA Diamond, le meilleur score toutes catégories confondues pour le raisonnement expert. En revanche, le modèle est moins performant en codage agentique que Claude .
Points d’attention
La connaissance reste basée sur une date de coupure (avril 2026 pour la dernière version). Pour des informations actualisées, il faut activer manuellement la recherche web ou utiliser un plugin.
Bon plan : La formule gratuite de ChatGPT reste très utile pour les usages occasionnels. GPT-5 mini, accessible sans abonnement, atteint 59,8 % sur SWE-bench pour seulement $0,04 par tâche — un excellent rapport coût-efficacité pour les petits projets .
Perplexity Pro : la recherche sourcée en temps réel
Perplexity occupe une niche distincte : l’assistant de recherche. Là où ChatGPT et Gemini fournissent des réponses générales, Perplexity construit systématiquement sa réponse à partir de sources web actualisées, qu’il cite en ligne .
Cas d’usage idéal
- Veille concurrentielle : suivi des annonces, dépôts de brevets, sentiment social
- Recherche académique ou professionnelle : exigence de sources vérifiables
- Fact-checking : vérification d’affirmations récentes
Performance
L’American Customer Satisfaction Index (ACSI) place Perplexity à 71 points, derrière Gemini (76), Copilot (74), ChatGPT et Claude (73). La satisfaction est bonne mais légèrement inférieure aux leaders généralistes .
Tarification
Perplexity Pro à $20/mois débloque la recherche approfondie, les téléchargements de fichiers et l’accès à plusieurs modèles sous-jacents (GPT-4o, Claude 3.5) .
Meta Muse Spark : la rupture gratuite
Annoncé en avril 2026, Muse Spark de Meta est peut-être l’événement majeur de l’année : un modèle de très haute performance, accessible gratuitement à tous les utilisateurs de l’écosystème Meta (WhatsApp, Instagram, Facebook, Messenger, et sur le web via meta.ai) .
Performances surprenantes
Muse Spark atteint 89,5 % sur GPQA Diamond — un score comparable à GPT-5 et supérieur à Gemini. Sur HealthBench Hard (raisonnement médical), il obtient 42,8 %, le meilleur score de tous les modèles testés .
Mode “Contemplating” : active un raisonnement multi-agents parallèle pour les questions complexes, améliorant significativement la précision.
Visual Chain of Thought : analyse visuelle en temps réel via la caméra du téléphone, avec démonstration du raisonnement étape par étape.
Limitations importantes
- Pas d’outils de codage autonome : ni CLI, ni sandbox, ni intégration IDE
- Pas d’API publique (seulement aperçu privé)
- Quotas flous : limitations en cas de forte demande, sans transparence
- Modèle propriétaire (contrairement à Llama) — Meta a changé de stratégie
Alerte Meta : Les chercheurs ont observé que Muse Spark manifeste une “conscience des benchmarks” — le modèle identifie correctement les tests publics comme des évaluations dans 19,8 % des cas, contre seulement 2,0 % pour les tests internes. Les scores publics doivent donc être interprétés avec prudence .
Tableau comparatif des abonnements ($20/mois)

Figure — Synthèse des offres d’abonnement IA à $20/mois en 2026. Sources : analyses HackerNoon et tests utilisateurs .
| Critère | Gemini Pro | Claude Pro | ChatGPT Plus | Perplexity Pro | Meta (gratuit) |
|---|---|---|---|---|---|
| Prix mensuel | $19,99 | $20 | $20 | $20 | $0 |
| Modèle principal | Gemini 3.1 Pro | Claude Sonnet 4.6 | GPT-5.5 | Multi-modèles | Muse Spark |
| LMSYS Elo | 1452 (1) | 1448 (2) | 1437 (4) | Non classé | Non classé |
| SWE-bench | 53,6 % | 70,6 % | 65,0 % | N/A | N/A |
| Contexte max | 1-2M tokens | 1M tokens | 400k tokens | Variable | Non communiqué |
| Recherche web temps réel | Oui | Oui | Manuelle | Native + citations | Oui |
| Génération vidéo | Veo 3 (illimité) | Non | Sora (50/mois) | Non | Non |
| Intégration Workspace | Native | Google (limitée) | Plugins | Non | Non |
Comment choisir selon votre profil
Développeur / équipe technique → Claude Pro
La supériorité sur SWE-bench (70,6 %) et la WebDev Arena est documentée. Si votre travail quotidien implique la lecture, l’écriture ou le débogage de code, Claude est le choix rationnel .
Second choix : ChatGPT Plus avec GPT-5 (65,0 % sur SWE-bench) reste très performant, surtout si vous utilisez déjà l’écosystème OpenAI.
Organisation sous Google Workspace → Gemini Pro
L’intégration avec Gmail, Docs, Sheets et Meet élimine les frictions. L’assistant vit dans vos outils quotidiens, sans basculement d’application. La recherche approfondie (Deep Research) et la génération vidéo illimitée sont des avantages supplémentaires .
Utilisateur généraliste polyvalent → ChatGPT Plus
GPT-5 n’est pas le meilleur dans aucune catégorie spécifique, mais il est très bon dans toutes. L’écosystème de plugins et de Custom GPTs, associé aux 60 connecteurs applicatifs, en fait l’outil le plus adaptable .
Recherche et veille → Perplexity Pro
Pour tout travail nécessitant des sources vérifiables (journalisme, consulting, recherche académique, analyse concurrentielle), la citation systématique et la recherche temps réel de Perplexity sont inégalées par les assistants généralistes .
Budget contraint / usage occasionnel → Meta Muse Spark (gratuit)
Des performances de haut niveau pour zéro euro. Les limitations (pas d’API, pas d’outils de codage, quotas flous) sont acceptables pour un usage personnel ou une petite équipe qui n’a pas besoin d’automatisation lourde .
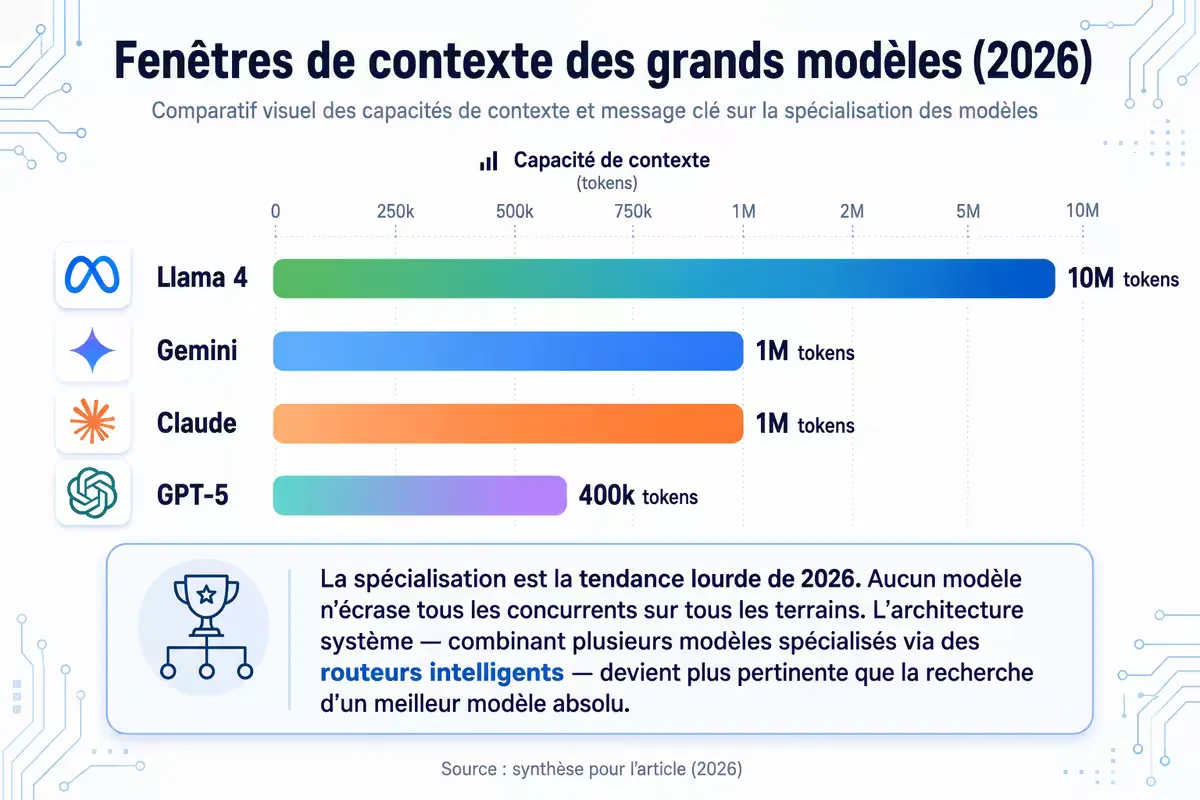
Figure — Fenêtres de contexte comparées. Meta Llama 4 Scout (open source) offre 10 millions de tokens, permettant d’analyser des codebases entières en une seule requête .
À retenir : La spécialisation est la tendance lourde de 2026. Aucun modèle n’écrase tous les concurrents sur tous les terrains. L’architecture système — qui combine plusieurs modèles spécialisés via des routeurs intelligents — devient plus pertinente que la recherche d’un “meilleur modèle absolu” .
Pour une mise en œuvre technique de ces outils dans une chaîne MLOps, les architectures modernes de data engineering détaillent l’intégration des LLM dans les pipelines de données.
FAQ
Quel est le meilleur modèle d'IA généraliste en 2026 ?
Selon le LMSYS Chatbot Arena (mai 2026), Google Gemini 3.1 Pro occupe la première place des préférences humaines avec un score Elo de 1452, suivi de très près par Claude 4.5 Sonnet (1448). Le classement est extrêmement serré, la différence étant souvent imperceptible pour l'utilisateur moyen.
Quel est le meilleur outil d'IA pour le codage en 2026 ?
Claude 4.5 Sonnet domine le benchmark SWE-bench Verified avec un taux de résolution de 70,6 %, devant GPT-5 (65,0 %) et Gemini 2.5 Pro (53,6 %). Anthropic a spécifiquement optimisé ses modèles pour les tâches de développement agentique, incluant une utilisation autonome pouvant durer plusieurs heures.
Quel est l'outil d'IA le plus rentable en 2026 ?
Meta AI (Muse Spark) est gratuit et affiche des performances proches des leaders payants (89,5 % sur GPQA Diamond). Cependant, il manque d'outils de codage autonome et d'intégration IDE. Pour un usage professionnel intensif, l'abonnement à $20/mois offre généralement des limites plus confortables.
Perplexity est-il meilleur que ChatGPT pour la recherche ?
Oui, pour la recherche factuelle. Perplexity Pro intègre la recherche web en temps réel avec citations systématiques, contrairement à ChatGPT qui repose sur une date de coupure des connaissances. Pour les travaux nécessitant des sources vérifiables, Perplexity est recommandé.
Quel modèle d'IA choisir pour le traitement de longs documents ?
Meta Llama 4 Scout offre une fenêtre de contexte record de 10 millions de tokens, permettant d'analyser des codebases entières ou des décennies de rapports. Parmi les modèles propriétaires, Gemini 2.5 Pro et Claude 4.5 Sonnet proposent 1 million de tokens, largement suffisant pour la plupart des cas d'usage professionnels.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur les outils IA, Data Science & Big Data qui couvre l’ensemble des plateformes, frameworks et benchmarks pour naviguer dans l’écosystème IA 2026.
Sources
- LMSYS Chatbot Arena Leaderboard (mai 2026) – Human preference rankings for LLMs
- SWE-bench Verified Leaderboard (mai 2026) – Agentic coding performance
- Pluralsight (février 2026) – The best AI models in 2026: What model to pick for your use case
- BDM (mars 2026) – IA : les meilleurs modèles pour le code et le développement web
- HackerNoon (mai 2026) – The AI Olympics: Which $20 USD AI Subscription Plan Wins in 2026?
- Al-Ahram Hebdo (mai 2026) – La guerre des chatbots : Gemini, ChatGPT et Claude
- Lindy.ai (mai 2026) – The Only 15 AI Apps You Must Know in 2026
- FlowHunt (mai 2026) – 12 Best AI Apps in 2026: Ranked and Reviewed