L’analyse exploratoire des données (EDA) est l’étape qui précède et éclaire tout projet de machine learning. Guide complet avec Python et R.
Résumé
L’analyse exploratoire des données (EDA) permet de comprendre la structure, les distributions, les relations et les anomalies d’un jeu de données avant la modélisation. Ce guide présente les étapes clés : statistiques descriptives, visualisations univariées (histogrammes, boxplots), analyses bivariées (scatter plots, matrices de corrélation), détection des valeurs aberrantes et manquantes. Tous les exemples sont fournis en Python (pandas, seaborn, plotly) et en R (tidyverse, ggplot2). Des bonnes pratiques pour automatiser l’EDA et l’intégrer dans un pipeline ML sont également discutées.
Table des matières
1. Qu’est-ce que l’EDA et pourquoi est-elle essentielle ?
L’analyse exploratoire des données (Exploratory Data Analysis) est une approche prônée par John Tukey dans les années 1970. Elle consiste à explorer visuellement et statistiquement un jeu de données avant d’appliquer des modèles complexes.
Pourquoi est-ce crucial ?
- Comprendre la qualité : valeurs manquantes, outliers, incohérences.
- Choisir les bonnes transformations : normalisation, encodage, traitement des asymétries.
- Orienter la modélisation : relations linéaires ou non, interactions potentielles.
- Communiquer : partager des insights avec les parties prenantes.
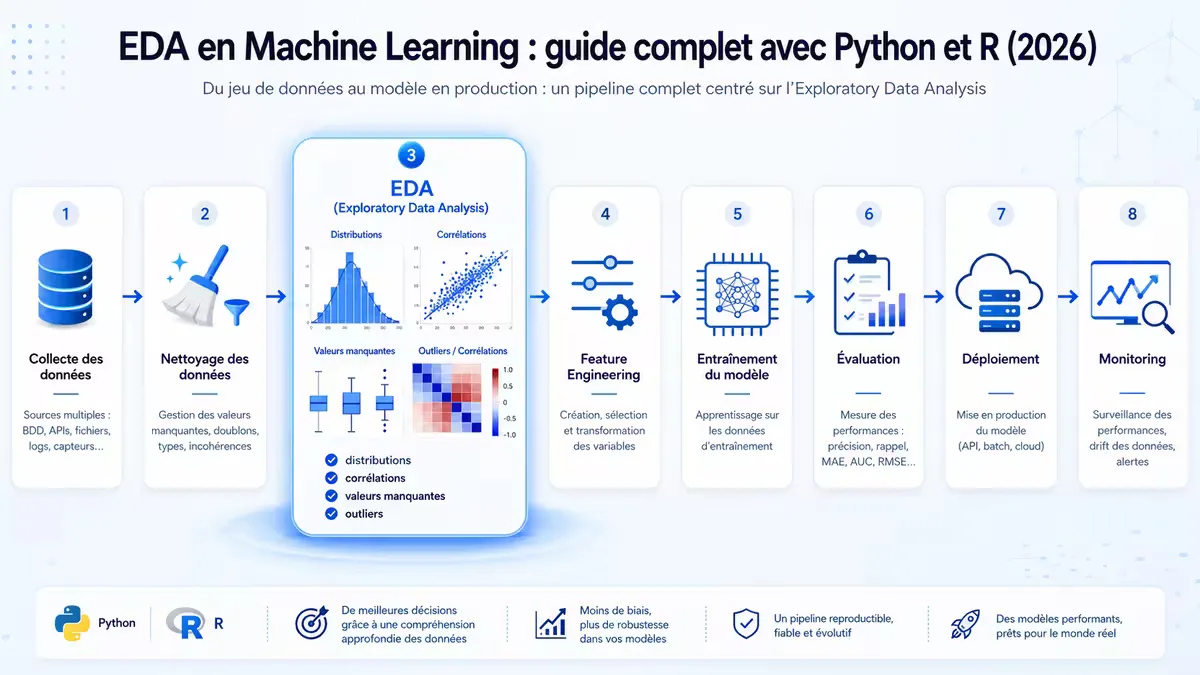
Figure 1 — Place de l’EDA dans le cycle de vie d’un projet de machine learning.
2. Les étapes clés de l’EDA
| Étape | Objectif | Exemples d’actions |
|---|---|---|
| Structure | Connaître dimensions, types, mémoire | df.shape, df.dtypes, df.info() |
| Statistiques univariées | Résumer chaque variable | df.describe(), df['col'].value_counts() |
| Visualisations univariées | Distribution, détection asymétrie | histogramme, boxplot, barplot |
| Valeurs manquantes | Localiser et quantifier | df.isnull().sum(), heatmap missingno |
| Outliers | Détecter les valeurs aberrantes | boxplot, IQR, z-score |
| Analyses bivariées | Relations entre paires | scatter plot, matrice de corrélation, pairplot |
| Analyses multivariées | Interactions complexes | heatmap, PCA, clustering exploratoire |
| Synthèse | Documenter les découvertes | rapport, notebook commenté |
3. EDA en Python : bibliothèques et exemples
Bibliothèques essentielles
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import missingno as msno
from ydata_profiling import ProfileReportChargement et première inspection
df = pd.read_csv('data.csv')
print(df.shape)
print(df.dtypes)
print(df.head())Statistiques descriptives
df.describe(include='all')
df['categorie'].value_counts(normalize=True)Visualisation des valeurs manquantes
msno.matrix(df)
plt.show()Histogrammes et boxplots
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
sns.histplot(df['age'], bins=30, ax=axes[0])
sns.boxplot(x=df['age'], ax=axes[1])
plt.show()Matrice de corrélation
corr = df.select_dtypes(include=np.number).corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.show()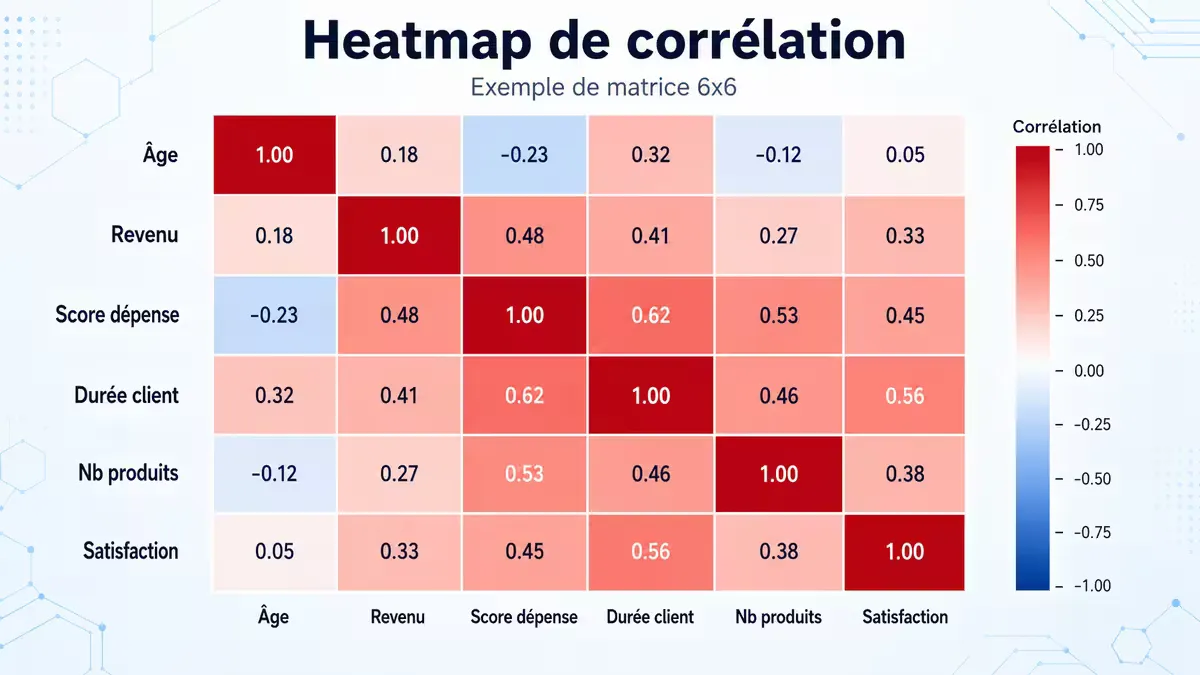
Figure 2 — Matrice de corrélation typique pour variables numériques.
Pairplot (seaborn)
sns.pairplot(df[['age', 'salaire', 'anciennete']], diag_kind='hist')
plt.show()Rapport automatique
profile = ProfileReport(df, title="EDA Report")
profile.to_file("eda_report.html")4. EDA en R : tidyverse et ggplot2
Bibliothèques
library(tidyverse)
library(skimr)
library(GGally)
library(DataExplorer)
library(visdat)Chargement et inspection
df <- read_csv('data.csv')
glimpse(df)
summary(df)Statistiques avec skimr
skim(df)Visualisation des manquants
vis_miss(df)Histogramme et boxplot avec ggplot2
ggplot(df, aes(x = age)) +
geom_histogram(bins = 30, fill = "steelblue") +
theme_minimal()
ggplot(df, aes(y = age)) +
geom_boxplot(fill = "steelblue") +
theme_minimal()Matrice de corrélation
df %>%
select(where(is.numeric)) %>%
cor() %>%
corrplot::corrplot(method = "color")Pairplot avec GGally
ggpairs(df, columns = c("age", "salaire", "anciennete"))Rapport automatique (DataExplorer)
create_report(df)5. Visualisations incontournables
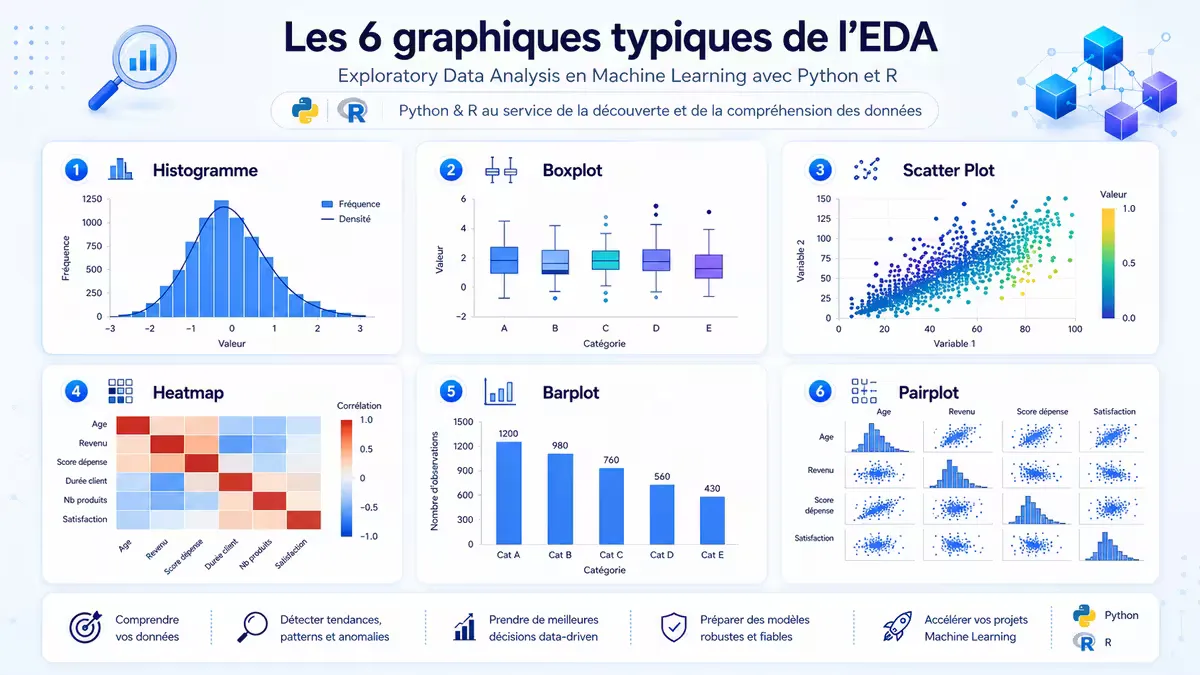
Figure 3 — Types de graphiques les plus utiles en EDA.
| Visualisation | Usage | Python | R |
|---|---|---|---|
| Histogramme | Distribution variable numérique | sns.histplot | geom_histogram |
| Boxplot | Détection outliers | sns.boxplot | geom_boxplot |
| Barplot | Distribution variable catégorielle | df['cat'].value_counts().plot(kind='bar') | geom_bar |
| Scatter plot | Relation deux variables | sns.scatterplot | geom_point |
| Heatmap | Corrélations | sns.heatmap | corrplot |
| Pairplot | Toutes paires de variables | sns.pairplot | ggpairs |
| Matrice de manquants | Visualisation NA | msno.matrix | vis_miss |
6. Automatiser l’EDA : profilage et rapports
Pour gagner du temps, des bibliothèques génèrent des rapports d’EDA complets en une ligne de code.
Python
- ydata-profiling : le plus complet. Génère un HTML avec analyses univariées, bivariées, alertes.
- sweetviz : permet de comparer deux datasets (train vs test).
- pandas-profiling (ancêtre, remplacé par ydata-profiling).
from ydata_profiling import ProfileReport
profile = ProfileReport(df, title="Analyse exploratoire")
profile.to_file("mon_rapport.html")R
- DataExplorer : crée un rapport HTML avec histogrammes, barplots, heatmap des corrélations.
- summarytools : génère des tableaux descriptifs pour la console ou HTML.
library(DataExplorer)
create_report(df, output_file = "rapport_eda.html")Attention : les rapports automatiques sont excellents pour une première vue, mais ne remplacent pas une analyse ciblée guidée par la connaissance métier.
7. Bonnes pratiques et pièges à éviter
✅ Bonnes pratiques
- Toujours commencer par
df.head()etdf.info(). - Visualiser avant de résumer : un tableau de statistiques peut masquer des distributions très différentes (ex: datasaurus dozen).
- Documenter chaque découverte : un notebook bien commenté est la meilleure trace.
- Séparer train et test avant toute EDA poussée (pour éviter le data leakage).
- Utiliser des couleurs et échelles cohérentes dans les graphiques.
❌ Pièges à éviter
- Ignorer les valeurs manquantes ou les traiter automatiquement sans comprendre leur origine.
- Confondre corrélation et causalité : une corrélation élevée n’implique pas de lien causal.
- Négliger les outliers sans les examiner (certains peuvent être des erreurs, d’autres des informations précieuses).
- Surcharger les visualisations (trop de variables sur un même graphique).
- Oublier les variables catégorielles dans les matrices de corrélation.
À retenir : L’EDA n’est jamais totalement terminée. Elle s’affine au fur et à mesure des questions que l’on se pose. Un bon data scientist passe autant de temps à explorer qu’à modéliser.
Revenir au guide complet
Cet article fait partie du guide complet sur la Data Science qui couvre l’ensemble du cycle de vie des données.
Articles connexes
FAQ
Quelle est la différence entre EDA et data cleaning ?
Data cleaning (nettoyage) corrige les erreurs, valeurs manquantes, doublons. L’EDA (exploratory data analysis) vient souvent avant et après le nettoyage : elle comprend des visualisations, statistiques descriptives, détection d’outliers, analyse de corrélations. En pratique, on alterne EDA et nettoyage.
Quels sont les meilleurs packages Python pour l’EDA ?
Les incontournables : pandas (manipulation), numpy (calcul), matplotlib et seaborn (visualisations statiques), plotly (interactif), missingno (visualisation des manquants), ydata-profiling (rapport automatique), sweetviz (comparaison datasets).
Quels sont les équivalents en R ?
Le tidyverse (dplyr, tidyr, ggplot2) est la référence. Pour l’EDA avancée : skimr (statistiques), corrplot (corrélations), GGally (paires de graphiques), DataExplorer (rapport automatique), visdat (visualisation des manquants).
Combien de temps prend une EDA typique ?
Pour un petit jeu de données (100 colonnes, 10k lignes), une EDA complète peut prendre 2 à 4 heures. Pour des données volumineuses ou complexes, plusieurs jours. Une EDA rapide (profilage automatique) peut se faire en quelques minutes.
Faut-il faire l’EDA avant ou après split train/test ?
L’EDA doit être faite uniquement sur l’ensemble d’entraînement pour éviter le data leakage. Vous pouvez analyser les statistiques globales, mais les décisions d’imputation, normalisation, etc., doivent être apprises sur le train et appliquées au test.
Les LLM peuvent-ils faire l’EDA à ma place ?
Ils peuvent générer du code d’EDA (histogrammes, boxplots, matrices de corrélation) et proposer des interprétations. Mais la partie décisionnelle (comment traiter une variable, quelle transformation) reste sous responsabilité humaine. Les rapports automatiques (ydata-profiling) restent plus fiables.
Sources
- Tukey, J. (1977) – Exploratory Data Analysis
- pandas documentation – Visualization
- seaborn – Examples gallery
- R for Data Science (Wickham, Grolemund)
- ydata-profiling – Documentation
- DataExplorer R package – Vignette
Article mis à jour le 28 mai 2026.