Les data scientists passent 80 % de leur temps à nettoyer et préparer les données. Comprendre pourquoi et comment réduire cette part.
Résumé
La donnée brute est rarement exploitable. Valeurs manquantes, formats incohérents, doublons, outliers, erreurs de saisie… le nettoyage des données (data cleaning) est l’étape la plus chronophage de tout projet data science. Cet article explique les causes de cette lourdeur, détaille les étapes typiques (inspection, imputation, dédoublonnage, standardisation), et propose des stratégies pour réduire ce temps : automatisation, outils de profilage, génération de code par LLM, et meilleures pratiques dès la collecte.
Table des matières
1. L’origine du chiffre 80 %
Le célèbre adage « 80 % du temps est consacré à préparer les données, 20 % à les analyser » remonte à des enquêtes auprès de data scientists (crowdflower, Forbes, Anaconda). Les raisons sont systémiques :
- Les données sont produites par des humains : saisies variables, erreurs de frappe, conventions différentes.
- Les systèmes de collecte sont fragmentés : ERP, CRM, logs, API, capteurs… chacun avec son propre format.
- Les données évoluent dans le temps : schémas qui changent, unités qui varient, valeurs absentes.
- La qualité n’est pas une priorité à la source : on collecte d’abord, on nettoie ensuite.
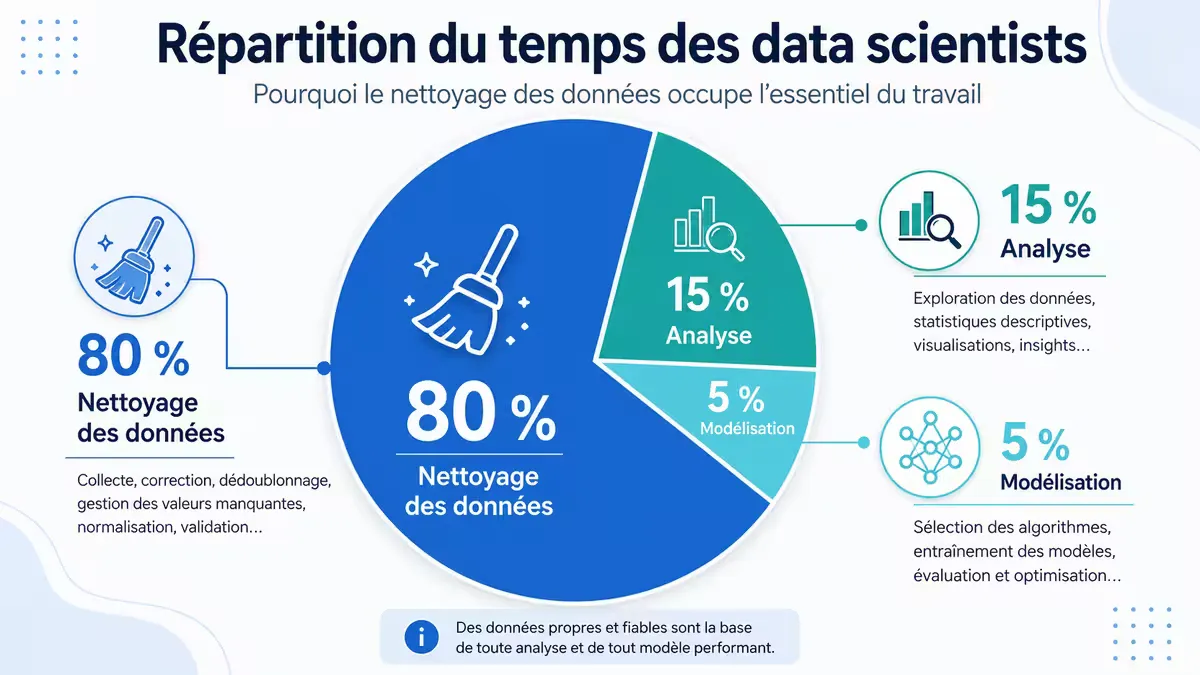
Figure 1 — Répartition typique du temps en data science. Le nettoyage est de loin la part la plus importante.
Une étude récente (Anaconda 2025) confirme : 78 % des data scientist interrogés passent plus de la moitié de leur temps à nettoyer les données. Seuls 22 % utilisent des outils d’automatisation avancés.
2. Les 7 familles de problèmes dans les données
| Problème | Exemple | Fréquence |
|---|---|---|
| Valeurs manquantes | age = NaN, adresse vide | Très fréquent |
| Format incohérent | Dates DD/MM/YYYY vs MM/DD/YYYYTéléphones avec/sans indicatif | Très fréquent |
| Doublons | Même client saisi deux fois avec des variations | Fréquent |
| Erreurs de saisie | ”Marseille” écrit “Marsaille”25 au lieu de 250 | Fréquent |
| Outliers | age = 999, salaire = -5000 | Occasionnel |
| Encodage / caractères spéciaux | Accents mal affichés (é pour é) | Occasionnel |
| Schéma implicite | Colonnes qui changent de sens selon la ligne | Rare mais grave |
3. Les étapes concrètes du nettoyage
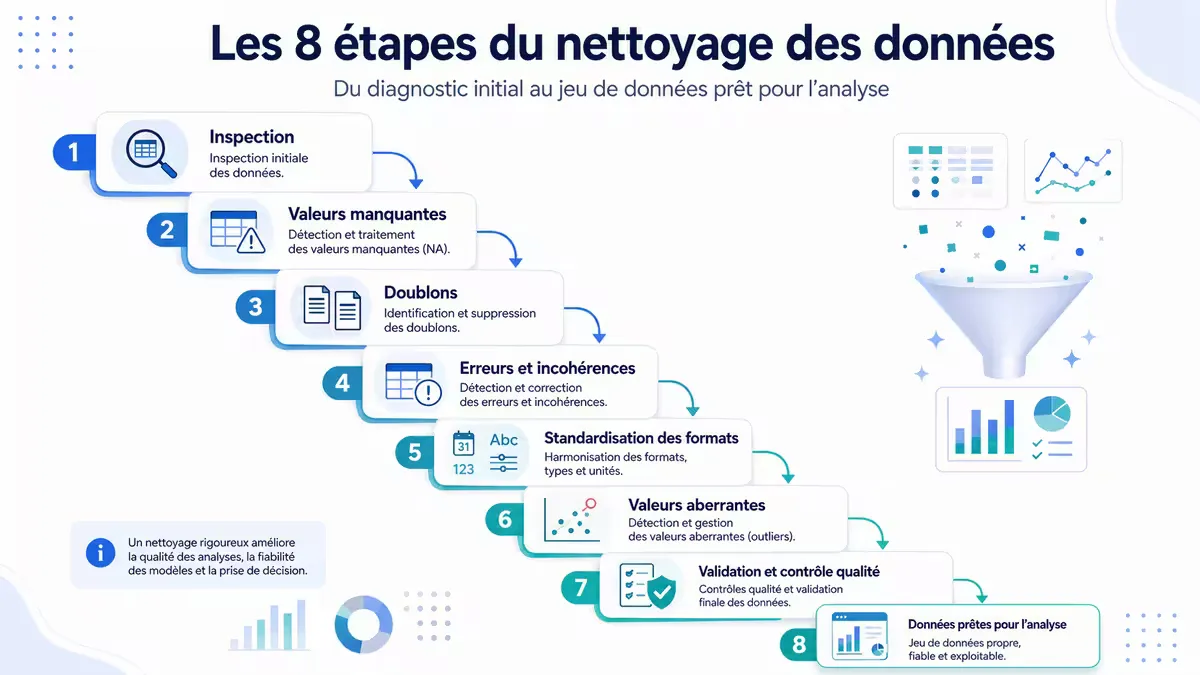
Figure 2 — Pipeline typique du nettoyage de données. Chaque étape peut nécessiter plusieurs aller-retours.
- Inspection :
df.head(),df.info(),df.describe(),df.isnull().sum(). - Traitement des valeurs manquantes : suppression (si peu) ou imputation (moyenne, médiane, valeur fréquente, modèle prédictif).
- Correction des types : dates en
datetime, catégories encategory, nombres enfloat/int. - Dédoublonnage :
df.drop_duplicates()ou détection floue pour les quasi-doublons. - Gestion des outliers : détection par IQR ou z-score, puis plafonnement (capping) ou suppression.
- Standardisation : mise en forme uniforme (minuscules, suppression espaces, unités cohérentes).
- Vérification de cohérence : règles métier (ex:
date_fin > date_debut). - Documentation : tracer chaque transformation (reproductibilité).
4. Exemple concret : nettoyer un fichier CSV
Prenons un fichier clients.csv contenant :
id,nom,age,ville,inscription
1,Dupont,35,Paris,2023-01-15
2,Martin,,Lyon,2023/02/20
3,Durand,quarante-deux,Marseille,2023-03-10
4,Dupont,35,Paris,2023-01-15
5,Petit,-5,Toulouse,2023-04-01Problèmes identifiés :
agemanquant (ligne 2), valeur texte (ligne 3), valeur négative (ligne 5)inscriptionformats mélangés (YYYY-MM-DD et YYYY/MM/DD)- doublon (lignes 1 et 4)
Script de nettoyage avec pandas :
import pandas as pd
df = pd.read_csv('clients.csv')
# 1. Nettoyer age : remplacer les valeurs non numériques par NaN, puis imputer la médiane
df['age'] = pd.to_numeric(df['age'], errors='coerce')
mediane_age = df['age'].median()
df['age'] = df['age'].fillna(mediane_age)
df.loc[df['age'] < 0, 'age'] = mediane_age # les âges négatifs deviennent la médiane
# 2. Standardiser les dates
df['inscription'] = pd.to_datetime(df['inscription'], errors='coerce')
# 3. Supprimer les doublons
df = df.drop_duplicates()
# 4. Vérifier
print(df.info())
print(df.head())5. Comment réduire ce temps ?
| Stratégie | Gain estimé | Mise en œuvre |
|---|---|---|
| Automatiser les contrôles de qualité | -30 % | Great Expectations, pandas-profiling |
| Standardiser les pipelines de nettoyage | -20 % | Fonctions réutilisables, DVC |
| Former les producteurs de données | -40 % (long terme) | Bonnes pratiques à la saisie, validations |
| Utiliser des LLM pour générer du code | -15 % | Prompts pour générer le nettoyage standard |
| Passer à des bases de données structurées | -25 % | Schémas stricts, contraintes d’intégrité |
Règle d’or : le meilleur nettoyage est celui qu’on n’a pas à faire. Investissez dans la qualité à la source (validations, schémas, tests).
6. Outils et bibliothèques incontournables
| Outil | Langage | Usage |
|---|---|---|
| pandas | Python | Nettoyage de base (manquants, types, doublons) |
| dplyr / tidyr | R | Data wrangling dans l’écosystème R |
| pandas-profiling (ydata-profiling) | Python | Rapport automatique des anomalies |
| Great Expectations | Python | Tests de qualité et documentation |
| OpenRefine | Interface graphique | Nettoyage interactif pour données sales |
| Trifacta (payant) | Interface | Nettoyage à grande échelle |
7. L’apport des LLM au nettoyage des données
Les LLM (GPT-5, Claude 4, Gemini 2.5 Pro) peuvent accélérer le nettoyage de plusieurs manières :
- Génération automatique de code à partir d’une description : « Écris un script pandas pour supprimer les doublons et remplacer les âges manquants par la médiane. »
- Détection de patterns complexes : expressions régulières, extraction d’entités, correction orthographique.
- Suggestions d’imputation : selon le contexte métier.
- Documentation des transformations : le LLM peut commenter chaque étape.
Exemple de prompt efficace
“J’ai un DataFrame pandas avec des colonnes ‘prix’ (parfois avec des virgules et des symboles €) et ‘date’ (format mixte JJ/MM/AAAA et AAAA-MM-JJ). Donne-moi un code pour nettoyer ces deux colonnes en flottant et datetime.”
→ GPT-5 produit un code robuste avec str.replace et pd.to_datetime.
Cependant, le LLM ne remplace pas la validation métier. Il est un assistant, pas un oracle.
Revenir au guide complet
Cet article fait partie du guide complet sur la Data Science qui couvre l’ensemble du cycle de vie des données.
Articles connexes
FAQ
Pourquoi le nettoyage des données prend-il autant de temps ?
Les données du monde réel sont rarement prêtes à l’emploi. Elles contiennent des valeurs manquantes, des doublons, des formats incohérents (dates, nombres), des erreurs de saisie, des outliers, et des schémas changeants. Chaque source de données a ses propres anomalies, et les comprendre demande une exploration minutieuse. Le nettoyage n’est pas une simple exécution de script : c’est un travail d’investigation itératif.
Quelles sont les étapes typiques du nettoyage de données ?
Les étapes standards : 1) inspection (head, info, describe), 2) traitement des valeurs manquantes (imputation ou suppression), 3) correction des types (dates, catégories), 4) détection et traitement des doublons, 5) gestion des outliers (valeurs aberrantes), 6) standardisation des formats (textes, unités), 7) vérification de la cohérence (contraintes métier), 8) documentation des transformations.
Le nettoyage peut-il être automatisé avec l’IA ?
Oui, de plus en plus. Des bibliothèques comme `pandas-profiling`, `Great Expectations` ou `dataprep` automatisent la détection. Les LLM (GPT-5, Claude 4) peuvent générer du code de nettoyage à partir d’une description. Des plateformes comme Trifacta ou OpenRefine proposent du nettoyage assisté. Mais une validation humaine reste nécessaire pour les règles métier complexes.
Combien de temps faut-il pour nettoyer un jeu de données typique ?
Cela varie énormément. Pour un petit CSV de 10 000 lignes bien formaté, 1 à 2 heures. Pour des données hétérogènes (fusion de plusieurs sources, logs, API), compter 1 à 5 jours. Dans les gros projets, le nettoyage peut prendre des semaines, surtout si les sources sont mal documentées.
Quelle est la différence entre data cleaning, data wrangling et data preprocessing ?
Data cleaning (nettoyage) corrige les erreurs et incohérences. Data wrangling (transformation) restructure les données pour l’analyse (fusion, pivot, aggrégation). Data preprocessing (prétraitement) prépare les données pour le machine learning (normalisation, encodage, réduction). Dans la pratique, ces étapes sont souvent mélangées.
Comment réduire le temps passé à nettoyer les données ?
Adoptez de bonnes pratiques dès la collecte (validation à l’entrée, schémas stricts). Utilisez des outils de profilage automatique. Standardisez vos pipelines de nettoyage avec des bibliothèques comme `pandas` ou `dplyr`. Formez les équipes à la qualité des données. Enfin, utilisez des LLM pour générer les scripts de nettoyage de base.
Sources
- Anaconda (2025) – State of Data Science Survey
- Crowdflower (2016) – Data Scientist Survey (origine du 80 %)
- McKinsey (2024) – The value of data quality
- Pandas documentation – Missing data handling
- Great Expectations – Best practices
Article mis à jour le 26 mai 2026.