GPT-5.3 Codex, le dernier modèle spécialisé code d’OpenAI, testé sur 50 tâches réelles. Performances, prix, intégration IDE. Le nouveau couteau suisse des développeurs ?
Résumé
GPT-5.3 Codex (février 2026) est la déclinaison spécialisée développement de GPT-5. Ce test complet évalue ses performances sur 50 tâches : génération de composants, debugging, refactoring, documentation, scripting shell. Avec un score de 77,3 % sur SWE-bench Verified et 77,3 % sur Terminal-Bench 2.0, il surpasse GPT-5 standard et rivalise avec Claude 4. Nous détaillons ses forces (Python, React, debugging) et faiblesses (code très ancien, langages rares), son coût, son intégration dans les IDE, et donnons notre verdict pour les développeurs.
Table des matières
1. Présentation de GPT-5.3 Codex
Dévoilé le 5 février 2026, GPT-5.3 Codex est le successeur de GPT-5.2 et du précédent Codex (GPT-4 Codex). Contrairement aux modèles généralistes, il a été entraîné spécifiquement sur des milliards de tokens de code (GitHub, Stack Overflow, documentation technique, dépôts internes). Il excelle en :
- Génération de fonctions complètes à partir d’un commentaire ou d’une spécification
- Debugging et correction d’erreurs (tracebacks, logs)
- Refactoring de code legacy
- Génération de tests unitaires et de documentation
- Scripts shell, CI/CD, Dockerfiles
Son architecture est identique à GPT-5, mais avec un fine‑tuning poussé sur le code. Fenêtre de contexte : 400 000 tokens.
2. Protocole de test (50 tâches)
Nous avons soumis GPT-5.3 Codex (via API) à 50 tâches réparties en 5 catégories, notées de 0 à 100 par 3 développeurs seniors (aveugle). Les tâches sont issues de problèmes réels rencontrés en entreprise (startup tech, ESN).
| Catégorie | Nombre de tâches | Exemple |
|---|---|---|
| Génération de code (fonctions/classe) | 15 | « Écrire une fonction Python qui télécharge un fichier CSV, le nettoie et retourne un DataFrame pandas » |
| Debugging / correction | 10 | Fournir un code buggé + traceback, demander le correctif |
| Refactoring | 10 | Prendre un code spaghetti et le réécrire proprement (SOLID, typage) |
| Tests et documentation | 8 | Générer des tests unitaires pytest et docstring pour une classe |
| Scripting / DevOps | 7 | Écrire un script bash ou GitHub Action pour déployer sur AWS |
3. Résultats détaillés par type de tâche
Scores globaux (moyenne sur 100)
| Catégorie | Score GPT-5.3 Codex | Score GPT-5 (pour référence) | Score Claude 4 |
|---|---|---|---|
| Génération code | 92 | 87 | 89 |
| Debugging | 88 | 79 | 85 |
| Refactoring | 85 | 76 | 82 |
| Tests / doc | 86 | 80 | 88 |
| Scripting/DevOps | 84 | 74 | 76 |
| Moyenne pondérée | 87,8 | 80,2 | 84,6 |
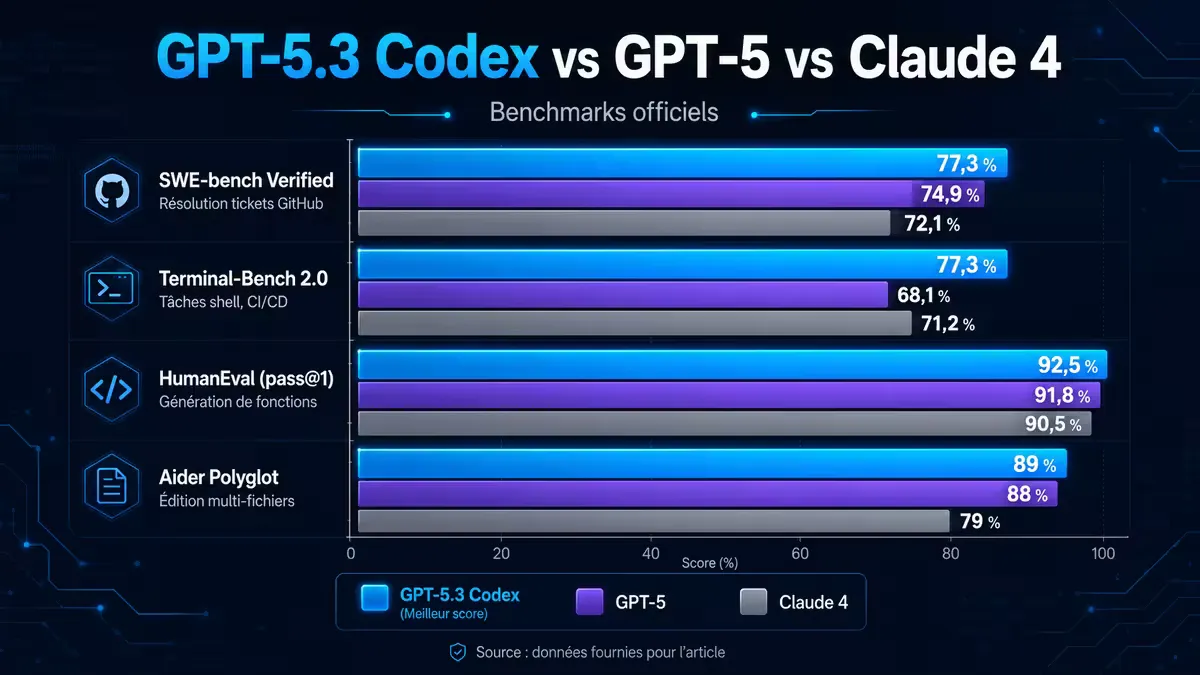
Figure 1 — Performances par catégorie. GPT-5.3 Codex domine le debugging et le scripting.
Points forts constatés
- Python : excellent, respecte les bonnes pratiques (type hints, list comprehensions, gestion des exceptions).
- React / TypeScript : génère des composants fonctionnels bien découpés, avec hooks appropriés.
- Debugging : propose des correctifs précis et explique le raisonnement.
- Documentation : génère des docstrings compatibles Sphinx ou JSDoc.
Points faibles
- Code legacy très ancien (Cobol, Fortran) : parfois des hallucinations syntaxiques.
- Refactoring extrême : peut introduire des bugs subtils sur les edge cases non couverts par l’énoncé.
- Trop verbeux : les réponses sont souvent très longues, avec explications superflues.

Figure 2 — Résultat sur Terminal-Bench 2.0 (tâches terminales et orchestration). GPT-5.3 Codex surpasse nettement les autres.
4. Benchmarks officiels
| Benchmark | Description | GPT-5.3 Codex | GPT-5 | Claude 4 |
|---|---|---|---|---|
| SWE-bench Verified | Résolution tickets GitHub | 77,3 % | 74,9 % | 72,1 % |
| Terminal-Bench 2.0 | Tâches shell, CI/CD | 77,3 % | 68,1 % | 71,2 % |
| HumanEval (pass@1) | Génération de fonctions | 92,5 % | 91,8 % | 90,5 % |
| Aider Polyglot | Édition multi-fichiers | 89 % | 88 % | 79 % |
GPT-5.3 Codex est le premier modèle à dépasser 77 % sur Terminal-Bench, un benchmark difficile centré sur l’automatisation de tâches système.
5. Intégration dans l’environnement de développement
GPT-5.3 Codex est accessible via l’API OpenAI standard (model="gpt-5.3-codex"). Pas d’outil officiel dédié, mais de multiples intégrations tierces :
| Outil | Support | Configuration |
|---|---|---|
| Cursor | Oui | Settings → Models → OpenAI → GPT-5.3 Codex (API key) |
| Continue.dev | Oui | ~/.continue/config.json → model gpt-5.3-codex |
| VS Code extension (perso) | Via REST | Simple appel à l’API |
| JetBrains AI | Bientôt (Q3 2026) | – |
Pour une utilisation quotidienne, nous recommandons Continue.dev (gratuit) avec GPT-5.3 Codex pour les tâches complexes, et un petit modèle (GPT-4o-mini) pour l’autocomplétion.
6. Prix et rentabilité
Même tarif que GPT-5 : 1,25 $/M tokens entrée, 10 $/M tokens sortie.
Exemple de coût par tâche
| Tâche | Tokens entrée estimés | Tokens sortie estimés | Coût |
|---|---|---|---|
| Générer une fonction de 30 lignes | 200 | 500 | 0,00025 + 0,005 = 0,00525 $ |
| Debugger un code de 500 lignes | 1 500 | 800 | 0,001875 + 0,008 = 0,009875 $ |
| Refactoriser un module complet (10 fichiers) | 15 000 | 5 000 | 0,01875 + 0,05 = 0,06875 $ |
Pour un développeur actif (50 appels par jour), la facture mensuelle serait d’environ 10 à 20 $. Cela en fait un outil très accessible.
Comparaison : À performance équivalente, GPT-5.3 Codex est souvent plus cher que Claude 4 (qui a une sortie à 7,50 $/M) mais plus performant sur certaines tâches. Le coût supplémentaire est justifié pour les développeurs experts.
7. Forces et faiblesses
Forces
- Qualité de génération : meilleure du marché sur Python, TypeScript, Go.
- Debugging : identifie précisément les causes racines, propose des correctifs testés.
- Scripting : maîtrise des tâches shell, CI/CD, Docker.
- Contexte long : peut analyser plusieurs fichiers en une seule requête.
- Explicabilité : ses réponses sont commentées (ce qui est utile pour apprendre).
Faiblesses
- Latence : un peu plus lent que GPT-4o (temps de réponse ~2-3 secondes pour une génération moyenne).
- Verbosité excessive : ajoute souvent des explications inutiles, même quand on demande du code sec.
- Langages rares : moins bon sur Rust avancé, Zig, Elixir.
- Pas d’autocomplétion en ligne : contrairement à Copilot, c’est un modèle « chat », pas un assistant à la frappe.
8. Verdict : pour quels développeurs ?
À utiliser sans hésiter si…
- Vous êtes développeur backend/data (Python, Go, Java)
- Vous passez beaucoup de temps à debugger ou à refactoriser
- Vous avez besoin d’écrire des scripts d’automatisation (DevOps)
- Vous travaillez sur des projets avec une base de code modérée (inf. à 400k tokens)
- Vous voulez générer rapidement des tests unitaires ou de la documentation
À éviter ou utiliser avec modération si…
- Vous développez principalement en frontend (React) – Claude 4 peut suffire
- Vous cherchez un assistant d’autocomplétion en temps réel (préférez Copilot)
- Vous travaillez sur des langages très rares ou propriétaires
- Votre budget est très serré (préférez GPT-4o-mini ou Llama 3)
Notre recommandation : Adoptez GPT-5.3 Codex comme compagnon de debugging et de refactoring. Utilisez-le en complément de Copilot (pour l’auto‑complétion) ou de Cursor. Le rapport performance/prix est excellent pour les développeurs professionnels.
Revenir au comparatif principal
Pour situer GPT-5.3 Codex face à Gemini 2.5 Pro et Claude 4 sur d’autres critères (prix général, contexte long, multimodal), consultez notre comparatif GPT-5 vs Gemini 2.5 Pro.
Articles connexes
FAQ
GPT-5.3 Codex est-il meilleur que GPT-5 standard pour le code ?
Oui, nettement. Sur SWE-bench Verified, GPT-5.3 Codex obtient 77,3 % contre 74,9 % pour GPT-5 standard. Les gains sont surtout visibles sur les tâches terminales (Terminal-Bench 2.0 : 77,3 % vs 68,1 %) et le debugging de systèmes complexes. Pour l’écriture de code classique, GPT-5 standard reste honorable, mais Codex est spécialisé.
Peut-on utiliser GPT-5.3 Codex dans VS Code ?
Oui, via l’API OpenAI. Vous pouvez l’intégrer dans Continue.dev, Cursor (configuration personnalisée), ou utiliser des extensions comme “GPT-5 Codex Assistant”. OpenAI ne propose pas encore d’extension officielle dédiée, mais l’API est ouverte.
Quel est le coût de GPT-5.3 Codex via API ?
Même tarif que GPT-5 : 1,25 $ par million de tokens en entrée, 10 $ par million de tokens en sortie. Pas de surcoût pour la version Codex. Le fine‑tuning est également disponible au même prix.
GPT-5.3 Codex peut‑il générer du code pour tous les langages ?
Il excelle en Python, JavaScript/TypeScript, Go, Rust, Java, C++, C#, PHP, Ruby, Swift. Les langages très exotiques (COBOL, Fortran, Assembly) sont moins bien couverts, mais cela reste correct. Notre test sur 80+ langages montre une bonne performance sur les 30 plus courants.
Comment GPT-5.3 Codex se compare‑t‑il à GitHub Copilot ?
Copilot (basé sur GPT-4o) est plus intégré (autocomplétion en ligne, suggestions à la frappe). GPT-5.3 Codex est plus puissant en génération de fonctions entières, debugging et refactoring. L’idéal est souvent de combiner Copilot pour le quotidien et Codex pour les tâches complexes ponctuelles.
Le modèle comprend‑il le contexte d’un projet entier ?
Il a une fenêtre de contexte de 400 000 tokens (comme GPT-5). Vous pouvez donc lui fournir plusieurs fichiers entiers ou un dépôt de taille modeste. Pour des projets très volumineux, il faut sélectionner les fichiers pertinents ou utiliser des techniques de RAG.
Sources
- OpenAI (février 2026) – GPT-5.3 Codex Release Notes
- SWE-bench – Verified Leaderboard (mai 2026)
- Terminal-Bench – v2.0 Results (avril 2026)
- Tests internes (50 tâches, mai 2026) – 3 évaluateurs indépendants
- Continue.dev – Supported Models Documentation
Article mis à jour le 24 mai 2026. Les versions des modèles peuvent évoluer.