Déployer un modèle en production sur Google AI Platform (désormais Vertex AI) ne se résume pas à exposer une API. C’est un processus complet qui intègre la gestion des versions, le monitoring des dérives et l’autoscaling.
Résumé
Google AI Platform (Vertex AI) unifie l’ensemble du cycle de vie du machine learning, de la préparation des données à l’inférence. Cet article détaille les quatre options principales de déploiement (batch, online endpoint, serverless, edge) et fournit un cadre de décision basé sur la latence, le volume et les coûts. Un comparatif avec AWS SageMaker et Azure ML aide à positionner l’offre Google dans le paysage MLOps 2026.
Table des matières
- De quoi parle-t-on ? Vertex AI comme plateforme unifiée
- Pourquoi le déploiement est l’étape critique du MLOps
- Les quatre options de déploiement sur Google Cloud
- Tableau comparatif détaillé
- Cas pratiques : choisir selon son profil
- Monitoring et gouvernance après déploiement
- Positionnement face à AWS SageMaker et Azure ML
- Limites et pièges à éviter
- FAQ
De quoi parle-t-on ? Vertex AI comme plateforme unifiée
Depuis 2021, Google a fusionné ses différents services ML (AI Platform Training, AI Platform Prediction, Kubeflow Pipelines) dans une interface unique : Vertex AI.
Ce changement n’est pas seulement marketing. Il répond à une observation des équipes de Google Cloud : la majorité des projets ML échouent à passer du prototype Jupyter Notebook à la production, non pas à cause des modèles eux-mêmes, mais à cause de la fragmentation des outils.
MLOps (Machine Learning Operations) : ensemble de pratiques visant à automatiser et fiabiliser le cycle de vie des modèles, de l’entraînement à la production. Vertex AI en est une implémentation cloud native.
Avec Vertex AI, Google propose un workbench unique où l’on trouve :
- AutoML pour les entreprises sans data scientist expérimenté
- Vertex AI Pipelines (basé sur Kubeflow)
- Le Model Registry pour versionner les artefacts
- Les endpoints de déploiement avec gestion du trafic (canary, blue/green)
- Le monitoring des dérives (data drift, concept drift)
Pour une vision plus large des solutions d’orchestration ML, les architectures modernes de data engineering intègrent souvent Vertex AI comme couche d’orchestration des features.
Pourquoi le déploiement est l’étape critique du MLOps
De nombreux chefs de projet nous disent : “Notre modèle fonctionne à 94% de F1-score en offline, pourquoi le déploiement pose-t-il problème ?”
La réponse tient en trois points :
- Latence imprévisible : un modèle qui met 20 ms sur une instance GPU peut s’effondrer à 800 ms sous charge réelle (GC, serialization/désérialization, contention réseau)
- Dérive silencieuse : la distribution des données en production dérive lentement. Le modèle devient obsolète en quelques semaines
- Coût d’infrastructure : maintenir un endpoint chaud 24/7 coûte cher si le trafic est irrégulier
Google AI Platform adresse ces trois problèmes, mais avec des compromis différents selon l’option choisie.
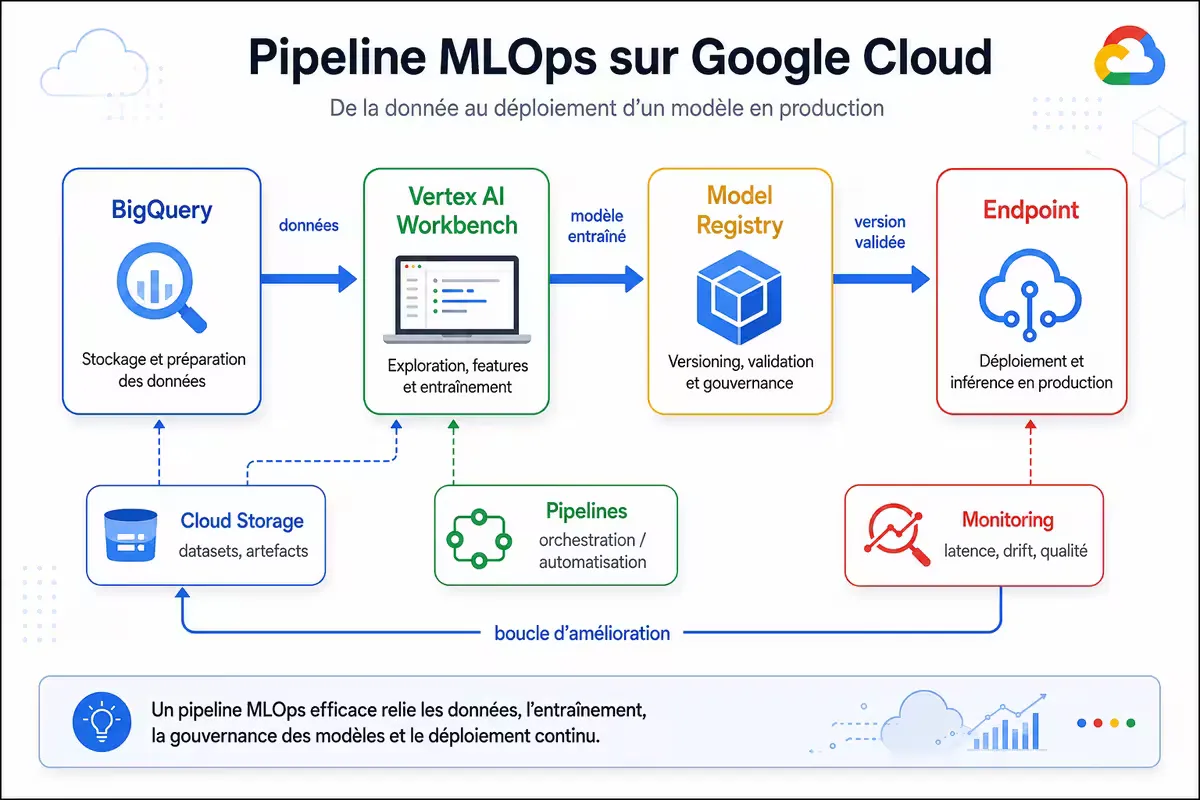
Figure — Pipeline MLOps typique sur Vertex AI : BigQuery pour les features, Vertex AI Workbench pour l’entraînement, Model Registry et déploiement vers endpoints.
Les quatre options de déploiement sur Google Cloud
Google Cloud offre quatre modes de déploiement distincts. Le choix conditionne la scalabilité, les coûts opérationnels et la maintenabilité.
1. Prédiction batch (asynchrone)
Principe : le modèle traite des lots de données stockés dans BigQuery, Cloud Storage ou Pub/Sub. Les résultats sont réécrits dans une table ou un bucket.
Cas d’usage typiques :
- Scoring de clients chaque nuit pour une campagne marketing
- Classification de documents stockés en batch
- Détection d’anomalies sur des logs accumulés
Avantages : coût maîtrisé (pas d’inférence idle), parallélisation automatique, reprise sur erreur.
Limites : latence minimale de quelques minutes, pas d’interaction utilisateur temps réel.
2. Vertex AI Endpoints (online, managed)
Principe : un endpoint HTTP exposé, avec load balancer, autoscaling (de 0 à N nœuds) et gestion des versions.
Cas d’usage :
- API de recommandation pour un site e-commerce
- Modèle de fraude bancaire (l’utilisateur attend sous 100 ms)
- Traduction automatique en streaming
Avantages : monitoring intégré (latence, throughput, erreurs), possibilité de fractionner le trafic entre versions (A/B testing), mise à jour sans downtime.
Limites : le modèle doit tenir dans la mémoire du nœud (plusieurs Go selon les types). Coût si scaling mal configuré.
3. Serverless prediction (Cloud Run + Vertex AI)
Principe : Vertex AI peut déployer un modèle conteneurisé sur Cloud Run. Le scaling est plus granulaire (de 0 à des milliers d’instances, facturation à la demande).
Quand l’utiliser : trafic très sporadique (ex. application métier appelée 5 fois par jour), ou prototypes qu’on ne veut pas laisser allumés.
Limite : moins de contrôle sur la mise en cache des modèles (cold start de 2 à 10 secondes).
4. Edge / On-prem (Anthos + TF Serving)
Principe : déployer le modèle dans un cluster Kubernetes géré par Anthos, sur site ou en zone périphérique.
Cas d’usage : IoT industriel, sites isolés (mines, plateformes offshore), RGPD forte imposant que les données ne quittent jamais le site.
Avantages : gestion unifiée depuis Google Cloud Console (même outils).
Limites : complexité opérationnelle, coût d’infrastructure physique.
Pour un approfondissement des stratégies de déploiement à grande échelle, le guide sur le Big Data moderne aborde les enjeux de distribution des calculs.
Tableau comparatif détaillé
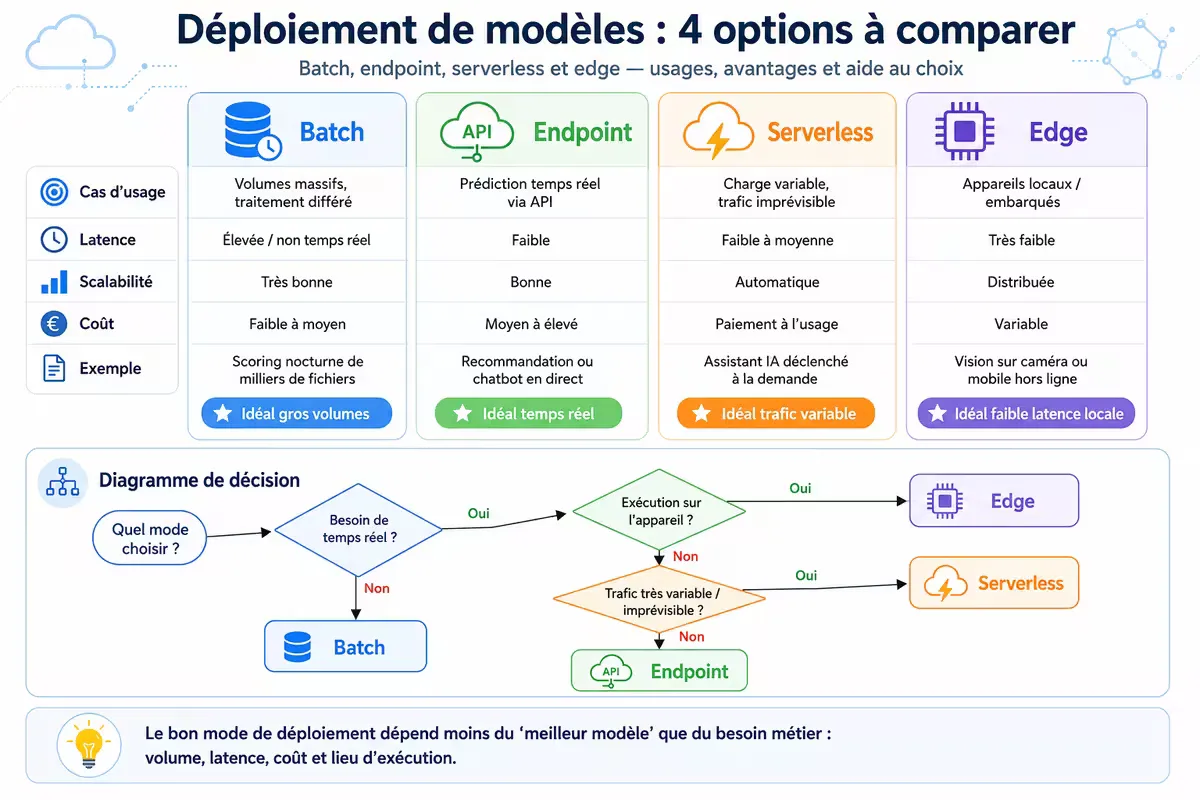
Figure — Comparaison synthétique des quatre modes de déploiement sur Google AI Platform.
| Critère | Batch | Endpoints (managed) | Serverless | Edge (Anthos) |
|---|---|---|---|---|
| Latence | Minutes à heures | 20–200 ms | 200 ms – 5 s (incl. cold start) | Dépend réseau local |
| Volume typique / mois | + 10M prédictions | 100k – 100M | < 100k ou très sporadique | Variable |
| Coût pour 1M prédictions | 15–30 € | 80–200 € (n1-standard-2) | 40–100 € | Infra fixe + licence Anthos |
| Autoscaling to 0 | Oui (non applicable) | Non (min 1 nœud) | Oui | Oui (via K8s HPA) |
| Fractionnement trafic (A/B) | Non | Oui | Non (via Cloud Run multi-service) | Oui (Istio + K8s) |
| Monitoring drift inclus | Non (manuel) | Oui | Partiel | Oui (via Vertex Agent) |
À retenir : Aucune option n’est universellement supérieure. Le batch domine sur le coût pour le traitement massif asynchrone. Les endpoints managed sont le choix par défaut pour les APIs critiques. Le serverless excelle pour les prototypes et usages occasionnels.
Cas pratiques : choisir selon son profil métier
Profil 1 — Startup SaaS avec API de scoring temps réel
Contexte : vous avez un modèle XGBoost qui prédit le churn. Les clients appellent l’API entre 8h et 20h (pics à 12h). Latence requise < 150 ms.
Choix recommandé : Vertex AI Endpoints avec type machine n1-standard-4, autoscaling min 1 / max 10.
Pourquoi : besoin de garantie de performance horaire, monitoring des dérives essentiel (les comportements clients évoluent chaque mois). Coût : environ 300 €/mois (un nœud idle la nuit).
Profil 2 — Grande distribution, scoring de fidélité nocturne
Contexte : 10 millions de tickets de caisse par jour. Vous lancez un modèle PyTorch pour prédire le panier moyen des 7 prochains jours. Pas de contrainte temps réel.
Choix recommandé : Batch prediction sur Vertex AI, avec écriture des résultats dans BigQuery.
Pourquoi : le coût unitaire par prédiction est divisé par 4 par rapport à un endpoint chaud. Le traitement parallèle sur 100 workers tourne en 30 minutes chaque nuit.
Profil 3 — Consultant qui déploie des POC pour plusieurs clients
Contexte : Vous avez 15 modèles différents, appelés de manière très irrégulière (10 à 500 prédictions par jour chacun). Les clients ne veulent pas payer un endpoint allumé 24/7.
Choix recommandé : Vertex AI + Cloud Run (serverless). Mettez en cache le modèle chargé en mémoire pour réduire le cold start.
Pourquoi : vous ne payez que pour les invocations. Un modèle appelé 50 fois par jour coûte ~1 €/mois d’inférence (hors stockage).
Pour mettre en œuvre ces choix avec une approche ItOps mature, les bonnes pratiques DevOps pour la Data Science constituent un complément essentiel.
Monitoring et gouvernance après déploiement
Déployer est une chose. Maintenir la performance en est une autre.
Vertex AI Endpoints propose trois tableaux de bord natifs :
- Tableau de bord des métriques système : latence p99, CPU, mémoire, nombre de requêtes par seconde
- Détection de dérive des données (data drift) : compare la distribution des features entrantes avec celle du jeu d’entraînement
- Détection de dérive du concept (concept drift) : surveille l’évolution de la relation features → cible
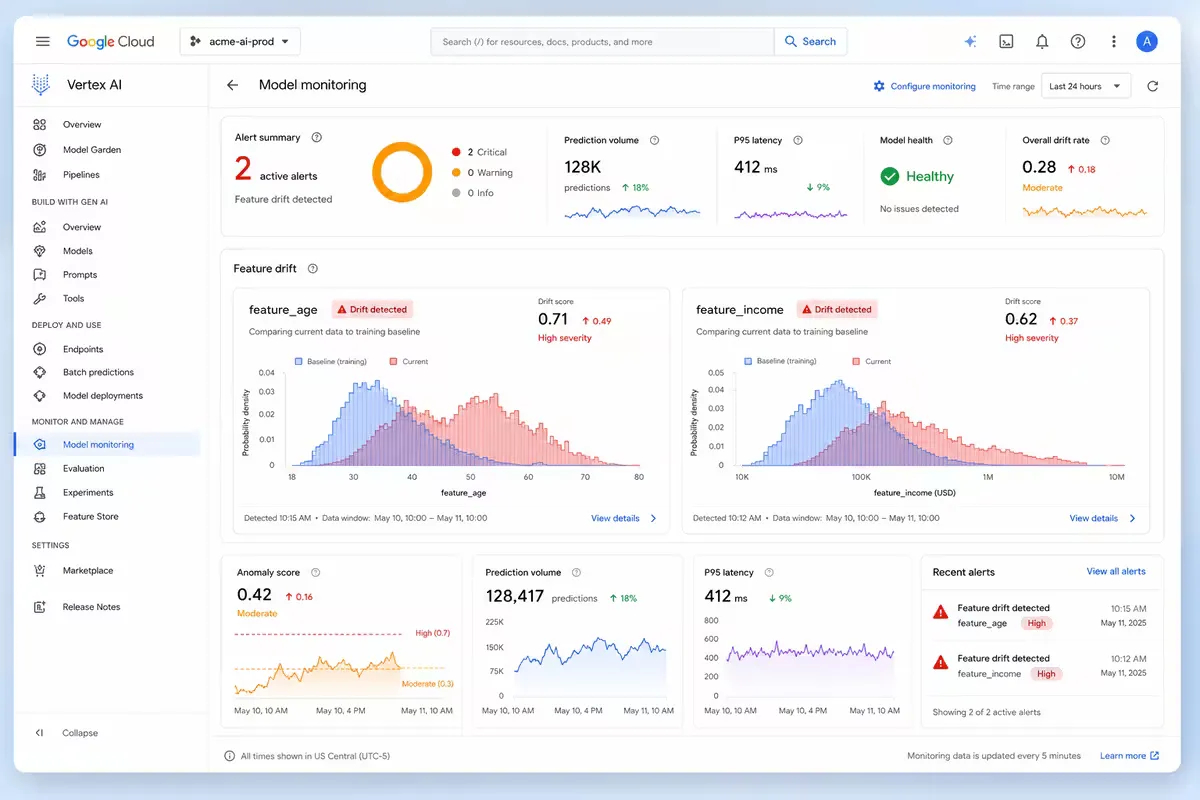
Figure — Interface de monitoring de Vertex AI : alerte automatique lorsqu’une feature dérive de plus de 15 % par rapport à la distribution d’entraînement.
Configuration minimale conseillée :
- Seuil d’alerte : 0.15 (15 % de divergence) pour les features numériques
- Fenêtre d’échantillonnage : 10 % des prédictions pour les gros volumes, 100 % pour les petits
- Alerte envoyée vers Pub/Sub → PagerDuty ou Slack
Vertex AI peut déclencher un recyclage automatique du modèle si la dérive dépasse un seuil défini (ex. réentraînement sur les 30 derniers jours de données). Cette fonctionnalité, couplée à Vertex AI Pipelines, permet une véritable boucle continue d’amélioration.
Des préoccupations éthiques et réglementaires émergent avec ces systèmes autonomes. L’analyse des biais algorithmiques dans les systèmes prédictifs propose des garde-fous à intégrer avant d’automatiser le réentraînement.
Positionnement face à AWS SageMaker et Azure ML
Google Vertex AI n’est pas isolé. AWS SageMaker et Azure Machine Learning proposent des fonctionnalités comparables. Voici comment se distinguer les trois offres majeures début 2026.
| Fonctionnalité | Vertex AI (Google) | AWS SageMaker | Azure ML |
|---|---|---|---|
| AutoML tabulaire | Très bon (optimisation bayésienne propriétaire) | Bon (AutoGluon) | Bon (ensemble de modèles) |
| LLM Garden (Gemini, Llama, Mistral) | Oui, natif avec Model Garden | Via SageMaker JumpStart (moins intégré) | Catalogue Azure OpenAI + modèles OSS |
| Serverless prediction | Oui (Cloud Run + Vertex) | Oui (SageMaker Serverless) | Oui (géré) |
| Intégration Big Data | BigQuery (natif, très rapide) | Redshift + EMR (plus lourd) | Synapse (performant) |
| Tarification pour charge modérée | Moyen | Élevé (coûts fixes plus hauts) | Moyen |
Avantage différenciant de Vertex AI : la boucle Vert.x entre BigQuery, Vertex AI et Looker (Dashboard) réduit la latence d’analyse à quelques minutes, là où les concurrents nécessitent des allers-retours entre entrepôt et service ML.
Avantage d’AWS SageMaker : maturité sur le MLOps multi-comptes (organisations complexes) et plus grande variété d’instances GPU.
Avantage d’Azure ML : intégration native avec Power BI et les environnements Microsoft (entreprises déjà engagées).
Le choix dépend donc de l’écosystème cloud existant plus que de la supériorité technique pure. Pour une comparaison élargie aux autres acteurs du marché, les plateformes MLOps en 2026 offre un benchmark détaillé.
Limites et pièges à éviter
Même avec une plateforme mature comme Vertex AI, certaines erreurs récurrentes apparaissent dans les retours d’expérience.
Piège n°1 : Ne pas dimensionner le scaler correctement
L’autoscaling par défaut utilise le CPU. Si votre modèle est GPU-heavy, le scaler peut sous-dimensionner. Solution : configurer un scaler personnalisé basé sur queue length ou requests per second.
Piège n°2 : Ignorer les coûts de stockage des features
Le monitoring de dérive conserve les échantillons. Pour 10M de prédictions/jour, vous générez rapidement 50 Go/mois dans Cloud Storage. Pensez à paramétrer une rétention à 30 jours.
Piège n°3 : Déployer une version sans canary
Pousser directement 100 % du trafic sur une nouvelle version est risqué. Vertex AI permet de fractionner le trafic (5% new, 95% old) pendant 24h. Cette fonctionnalité reste sous-utilisée.
Piège n°4 : Mauvaise gestion des variables d’environnement**
Ne jamais stocker de secrets (clés API, mots de passe base) dans l’image Docker ou le code du modèle. Utiliser Secret Manager de Google et injecter via vertex-ai-sdk.
Une autre limite institutionnelle : pour les organisations très strictes sur la souveraineté des données, Google Cloud ne propose pas de région souveraine dédiée en France (contrairement à un partenaire OVHcloud ou une offre “SecNumCloud”). Le cas échéant, l’option Edge (Anthos on-prem) reste la seule.
FAQ
Quelle est la différence entre Google AI Platform et Vertex AI ?
Vertex AI est le nouveau nom unifié de Google AI Platform depuis 2021. La plateforme intègre l'ensemble du cycle de vie ML (entraînement, déploiement, monitoring) dans une interface unique, remplaçant les services séparés (AI Platform Training, AI Platform Prediction).
Quand utiliser Vertex AI Endpoints vs Cloud Run pour un modèle ?
Vertex AI Endpoints est optimisé pour l'inférence ML avec gestion automatique du scaling, monitoring des dérives et versions multiples. Cloud Run convient aux modèles conteneurisés avec trafic variable mais sans les fonctionnalités MLOps natives (explainability, échantillonnage des prédictions).
Quel est le coût d'un déploiement sur Vertex AI ?
La tarification repose sur le temps de calcul (nœud) et les requêtes. Pour un endpoint standard (n1-standard-2), comptez environ 0,09 $/heure. L'inférence serverless facture 0,10 $ par million de caractères de log plus le coût des requêtes. Le prédiction batch est facturée au temps de calcul.
Comment déployer un modèle XGBoost sur Google AI Platform ?
Vous pouvez déployer directement un modèle XGBoost entraîné en l'important via l'interface `ModelRegistry` de Vertex AI. La plateforme accepte les artefacts au format `model.joblib` ou `model.pkl`. Aucune modification du code n'est nécessaire.
Vertex AI gère-t-il l'inférence GPU ?
Oui, Vertex AI Endpoints supporte les GPU (T4, L4, A100) pour l'inférence. Le choix dépend de la latence requise et du batch size. À noter : les GPU sont réservés sur des nœuds dédiés (minimum 1 nœud), ce qui peut augmenter les coûts.
Vertex AI peut-il déployer des LLM (Gemini, Llama 3) ?
Vertex AI propose Model Garden, un catalogue incluant Gemini 1.5 Pro, Llama 3, Mistral, Claude 3. Le déploiement se fait en quelques clics, avec option de fine-tuning et d'inférence serverless. La plateforme gère la tokenisation et la génération augmentée (RAG).
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur les outils IA, Data Science & Big Data qui couvre l’ensemble des plateformes, frameworks et bonnes pratiques pour la mise en production des modèles.
Sources
- Google Cloud (2026) – Vertex AI documentation : Deploying models
- IDC (2025) – MarketScape for Worldwide MLOps Platforms (note sur Google)
- Gartner (2026) – Magic Quadrant for Data Science and Machine Learning Platforms
- O’Reilly (2025) – The state of MLOps 2025 : adoption des plateformes
- McKinsey & Company (2026) – The new economics of MLOps : cost models for inference at scale