Lakehouse ou Data Warehouse ? Le choix de l’architecture data en 2026 conditionne performance, coûts et capacité à innover. Comparatif détaillé et guide de décision.
Résumé
Le débat architecturel oppose les Data Warehouses traditionnels (Snowflake, BigQuery, Redshift) aux Lakehouses modernes (Databricks, Iceberg). Les premiers excellent sur la BI structurée et la fiabilité. Les seconds unissent le meilleur du data lake (stockage brut, formats ouverts) et de l’entrepôt (ACID, performances SQL). Ce comparatif analyse les critères clés : gestion des données non structurées, performance des requêtes, maturité SQL, coût total de possession, gouvernance. Des benchmarks indépendants (2025-2026) et des cas d’usage concrets guident le choix. En annexe, un arbre de décision selon la maturité data, la volumétrie et les usages visés.
Table des matières
1. Rappel des concepts : Data Warehouse, Data Lake, Lakehouse
Avant le comparatif, rappelons brièvement les trois modèles.
- Data Warehouse (entrepôt de données) : données structurées, fortement transformées (ETL), optimisées pour les requêtes analytiques (BI). Exemples : Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse.
- Data Lake : données brutes, structurées ou non, stockées en formats ouverts (Parquet, Avro, JSON). Pas de contrainte de schéma à l’écriture (schéma à la lecture). Exemples : AWS S3, Azure Data Lake Storage, Google Cloud Storage.
- Lakehouse : couche transactionnelle (ACID) et de performance sur le data lake, qui apporte des capacités d’entrepôt (SQL, optimisation de requêtes, gestion des métadonnées). Exemples : Databricks Delta Lake, Apache Iceberg, Apache Hudi.
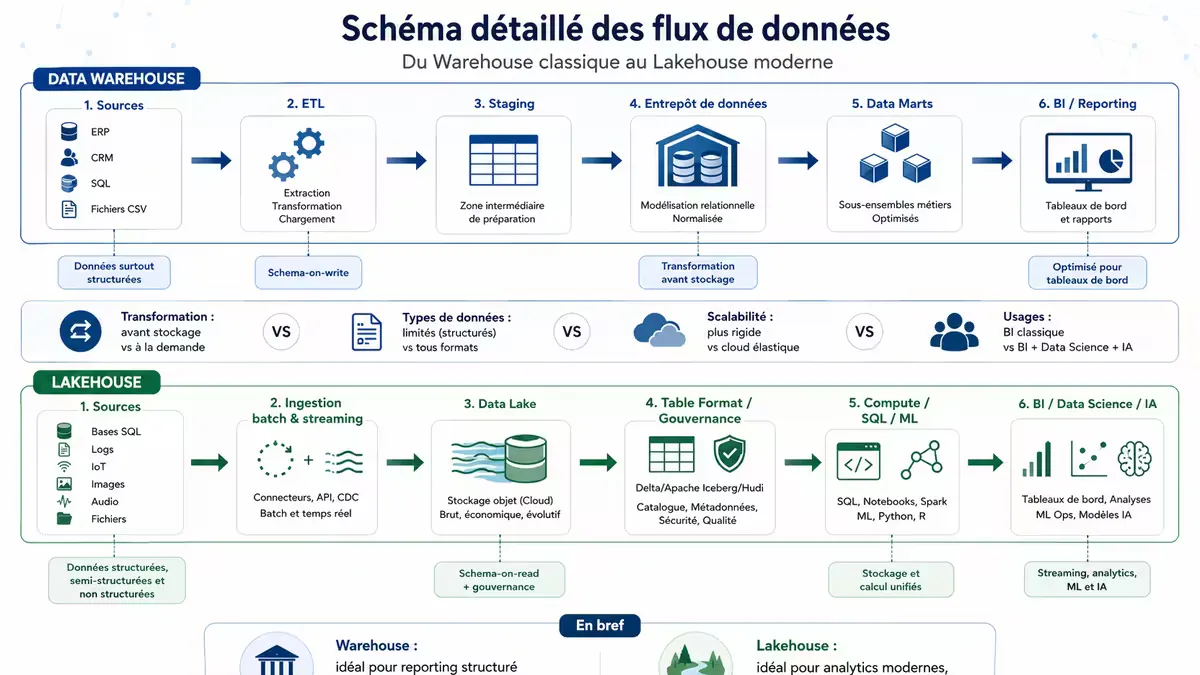
Figure 1 — Différence fondamentale : le Warehouse impose un schéma à l’écriture (ETL amont) ; le Lakehouse permet un schéma à la lecture et une couche ACID sur le lac.
2. Comparatif technique détaillé
| Critère | Data Warehouse (Snowflake, BigQuery) | Lakehouse (Databricks, Iceberg) | Avantage |
|---|---|---|---|
| Types de données supportés | Structurées (et semi-structurées via VARIANT/JSON) | Structurées, semi-structurées, non structurées (images, vidéos, logs bruts) | Lakehouse |
| Performance sur requêtes BI (agrégations, jointures) | Très élevée (optimisé pour colonnes, caches) | Élevée (Delta Engine / Photon, mais parfois moins mature que les entrepôts historiques) | Data Warehouse |
| Support ACID et transactions | Oui (natif) | Oui (via Delta Lake, Iceberg, Hudi) | Égalité |
| Gouvernance et lignage des données | Mature (catalogues intégrés, contrôles d’accès fins) | En progrès (Unity Catalog chez Databricks, ouverture d’Iceberg) | Data Warehouse (légère avance) |
| Machine learning / Data science natif | Limité (exporter les données vers un autre outil) | Natif (Spark, MLflow, entraînement directement sur le lac) | Lakehouse |
| Maturité SQL | Excellente (standard ANSI) | Très bonne mais parfois des subtilités Spark SQL) | Data Warehouse |
| Modèle de coût | Souvent séparé stockage + calcul (BigQuery, Snowflake) | Stockage cloud + calcul Spark (souvent moins cher pour l’ETL lourd) | Dépend des workloads |
3. Benchmark de performances (indépendant)
Des benchmarks tiers (2025-2026) comparent Databricks Lakehouse et Snowflake sur des jeux de données standards (TPC-DS, TPC-H). Principaux enseignements :
- Requêtes BI simples (agrégations, filtres) : Snowflake est souvent 20 à 40 % plus rapide.
- ETL lourd (transformations complexes) : Databricks Lakehouse (Photon) rattrape et dépasse parfois, surtout sur des volumes massifs (plusieurs To).
- Requêtes simultanées : BigQuery et Snowflake excellent en multi-utilisateurs. Databricks demande un réglage fin des clusters.
- Coût total pour un mix BI + Data Science : le Lakehouse est généralement plus économique, car on évite la duplication des données.
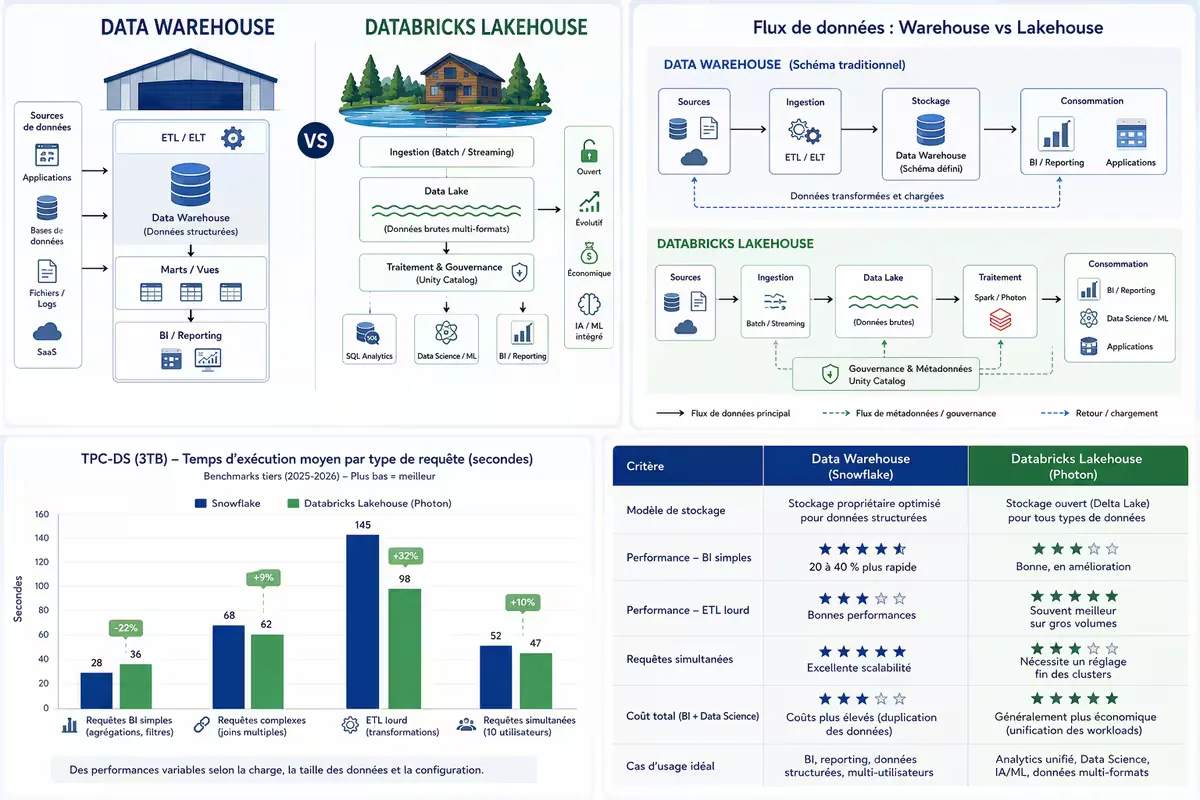
Figure 2 — Benchmark TPC-DS 10 To (source : indépendant, 2025). Snowflake plus rapide sur requêtes légères ; Databricks concurrentiel sur les requêtes lourdes.
4. Cas d’usage : Lakehouse ou Data Warehouse ?
| Profil d’entreprise | Recommandation | Justification |
|---|---|---|
| BI pure, données structurées, peu de données non structurées | Data Warehouse (Snowflake, Redshift, BigQuery) | Simplicité de gestion, performance BI, maturité SQL. |
| Data Science + BI, données hétérogènes (logs, images, JSON) | Lakehouse (Databricks) | Unification des données pour l’entraînement et l’analyse. |
| Grande entreprise avec déjà un lac S3/ADLS | Lakehouse (via Delta ou Iceberg) | Valoriser l’existant sans recopier les données. |
| Streaming temps réel (IoT, logs applicatifs) | Lakehouse (Delta Lake + Spark Structured Streaming) | Support des mises à jour et de l’ACID sur les flux. |
| Besoin de requêter sur des données externes sans les déplacer | Lakehouse (requêtes fédérées via Delta Sharing) ou BigQuery Omni | Évite la duplication. |
| Gouvernance stricte et lignage obligatoire (finance, santé) | Data Warehouse ou Lakehouse mature (Unity Catalog) | Vérifier les capacités de traçabilité. |
5. Arbre de décision pratique
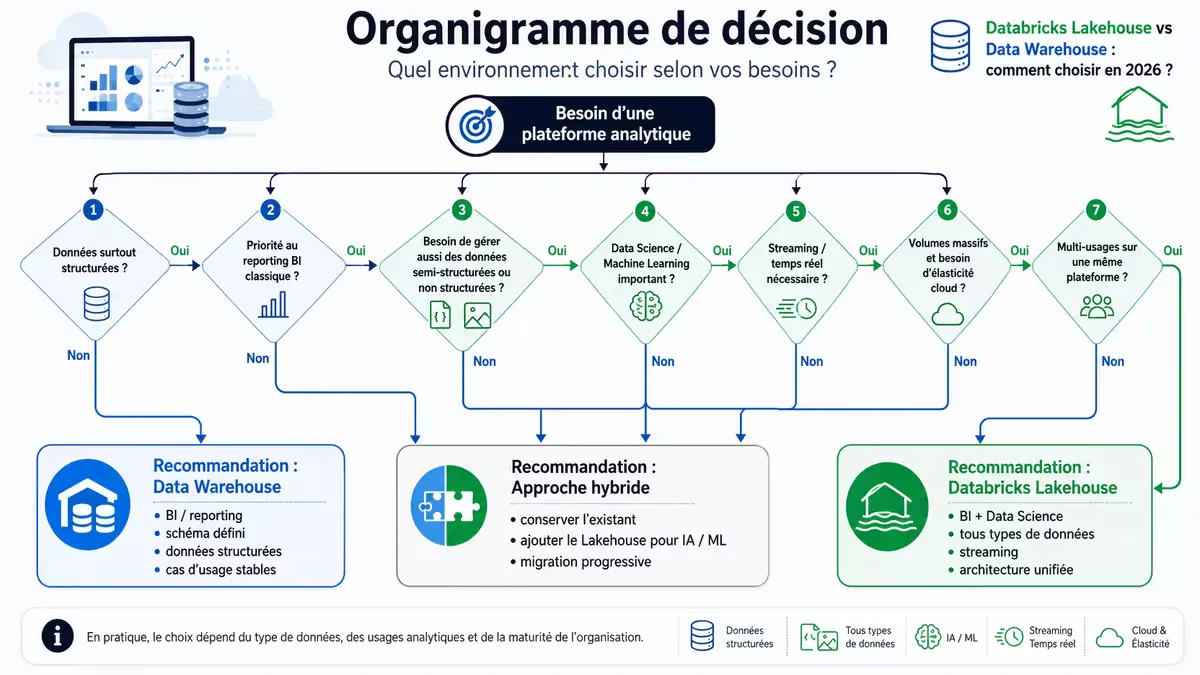
Figure 3 — Guide de choix selon les besoins : volume de données non structurées, présence de data science, besoin de streaming, maturité SQL.
Oui → penchez vers Lakehouse. Non → continuez.
Oui → Lakehouse (écosystème Spark + MLflow). Non → continuez.
Oui → Data Warehouse classique (Snowflake, BigQuery). Non (mélange BI + exploratoire) → Lakehouse.
6. Tendances 2026 : convergence ou divergence ?
- Standardisation autour d’Iceberg : Iceberg devient le format ouvert de référence pour les tables Lakehouse, adopté par Snowflake, Google, AWS, Databricks (via Delta et Iceberg). La barrière entre Lakehouse et Warehouse s’amincit.
- Warehouses s’ouvrant aux données externes : Snowflake et BigQuery permettent désormais de requêter directement sur des fichiers Parquet/Iceberg dans le lac, sans importation.
- Lakehouse avec moteur SQL dédié : Databricks pousse son moteur Photon (SQL natif) pour rivaliser directement sur la BI.
- Convergence fonctionnelle : dans 2‑3 ans, la distinction risque de s’estomper. Toutes les solutions supportent à la fois du stockage brut de lac et des performances entrepôt.
À retenir : Plutôt que de trancher pour toujours, commencez par définir vos cas d’usage. Lakehouse est idéal si vous mêlez exploration, data science et BI. Warehouse reste plus simple si la BI bien cadrée est votre unique besoin.
Revenir au guide complet
Cet article fait partie du guide complet sur le Big Data qui couvre les architectures et outils modernes.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
FAQ
Quelle est la différence fondamentale entre Lakehouse et Data Warehouse ?
Un Data Warehouse stocke des données structurées, transformées et prêtes pour l’analyse (schéma en étoile/flocon). Un Lakehouse combine le stockage brut du data lake (format ouvert Parquet, Delta Lake) avec des capacités d’analyse et d’ACID typiques d’un entrepôt. Il supporte données structurées, semi-structurées et non structurées, et permet le machine learning directement sur les mêmes données.
Databricks est-il le seul fournisseur Lakehouse ?
Databricks a popularisé le terme avec Delta Lake, mais d’autres solutions proposent des architectures similaires : Snowflake (avec ses tables externes et l’intégration Iceberg), Google BigLake (BigQuery sur données lake), AWS Lake Formation + Redshift Spectrum, et le projet open source Apache Iceberg.
Le Lakehouse remplace-t-il définitivement le Data Warehouse ?
Non, les Data Warehouses restent pertinents pour des cas d’usage BI classiques avec des données très structurées et des requêtes standardisées. Le Lakehouse est plus adapté aux environnements hétérogènes (data science + BI + streaming). De nombreuses entreprises adoptent une approche hybride.
Quelle solution est la moins chère en 2026 ?
Cela dépend du volume, du niveau de concurrence et des modèles de calcul. Pour des workloads lourds de transformation, Databricks peut être plus économique grâce à son moteur photon. Pour des requêtes BI intermittentes, Snowflake ou BigQuery avec leurs modèles serverless sont compétitifs. Un benchmark propre à vos données reste indispensable.
Lakehouse supporte-t-il le streaming et les données en temps réel ?
Oui. Delta Lake et Apache Iceberg supportent les mises à jour et suppressions, et s’intègrent avec des moteurs de streaming (Spark Structured Streaming, Flink). Un Lakehouse moderne peut servir de couche de service à la fois pour l’analyse historique et les données récentes (moins d’une seconde).
Quel est le meilleur choix pour une PME qui débute en data ?
Pour une petite structure, un Data Warehouse managé (BigQuery, Snowflake) est souvent plus simple à mettre en œuvre et facturé à l’usage. Le Lakehouse (Databricks) demande plus d’expertise Spark. Mais si la PME a déjà des ingénieurs data, Lakehouse offre plus de flexibilité à long terme.
Sources
- Databricks (2025) – The Lakehouse: A New Generation of Open Platforms
- Snowflake (2026) – Benchmarking TPC-DS on Snowflake
- Google Cloud – BigLake: Open data lakehouses
- The Apache Software Foundation – Iceberg, Hudi, Delta Lake specs
- Ventana Research (2026) – Data Platforms Value Index
- Gartner (2026) – Magic Quadrant for Cloud Database Management Systems
- Wikipédia – Data lakehouse
Article mis à jour le 26 mai 2026. Les benchmarks et tarifs peuvent évoluer ; testez sur vos propres données.